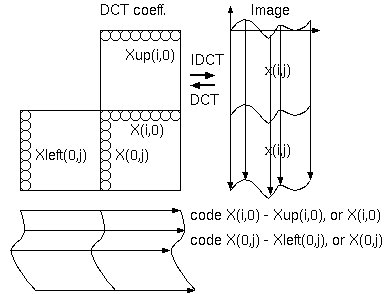
図1. MPEG-4 のイントラ DC-AC 予測
目次
1. フレーム間予測と動き補償 MC-DCT
1.1 予測誤差を変換
1.2 複雑な符号化モード
2. イントラ符号化
2.1 MPEG-4 の intra DC-AC予測
2.2 H.264のイントラ予測
2.3 予測モードの推定
2.4 イントラ予測のその後
3. 予測サイズと変換サイズ
3.1 予測ブロックサイズ
3.2 変換ブロックサイズ
3.3 MC-DCTの相性のよさ
4. 固定MB、スキップMB、ダイレクト予測、動きマージ
4.1 ダイレクト予測
4.2 動きベクトル予測(MVP)
4.3 HEVC、4分木とスキップ/動きマージ/AMVPとの組み合わせ
4.4 タイル(Tile)
5. 量子化と逆量子化
5.1 mquant と QM
5.2 QM の設定方法
5.3 dQP の符号化
6. MPEG-1:B画像
6.1 B画像
6.2 半画素精度MC
6.3 2段階双方向
7. MPEG-2:インターレースと階層符号化
8. MPEG-4
8.1 MPEG-4 のオブジェクト符号化
9. H.264、MPEG-4AVC からHEVCへ
9.1 CABAC算術符号化
9.2 レート歪最適化(RDO)
9.3 適応ループフィルタ(ALF)
9.4. 画素適応オフセット(SAO)
10. その他の技術
表1. ITU-TとISO/IEC SC29/WG11(MPEG)関連、動画像符号化標準と、導入された技術
| 符号化標準: | 導入された符号化技術 |
|---|---|
| H.261: | MC-DCT。2次元VLC、GOB、マクロブロック、mquant、CBP |
| JPEG: | DCTと量子化マトリクス、2次元(run-size)VLC |
| MPEG-1: | MC-DCTに双方向予測、半画素予測、スライス |
| MPEG-2(H.262): | フレーム/フィールド予測、DCTtype、Dual'予測と、スケーラビリティ(空間、SNRなど) |
| H.263: | イントラDC-AC予測、3DVLC、枠制限無(unrestricted)MC、など多くの技術 |
| JPEG2000: | 離散Wavelet変換(DWT)にEBCOT符号化、ビットプレーン、ROI符号化 |
| MPEG-4: | オブジェクトベース符号化(形と模様)、イントラDC-AC予測、1/4画素予測 |
| MPEG-4 AVC(H.264): | マルチフレーム予測とイントラ予測、4x4 DCT(整数変換) 逆スキャン符号化、ループ内デブロック |
| HEVC: | 4分木(quadtree) による画像分割、タイル、スキップ/動きマージ/AMVPの複数候補選択、SAO |
| JCT3V: | デプス画像を用いる3D多視点符号化 |
HEVC の JCT-VC 会合全書類は公開され、Webで閲覧できる。
FTPサイト: http://wftp3.itu.int/av-arch/jctvc-site/
全会合の文書の題名の用語検索と著者検索ができる "Welcome to JCT-VC" は、
http://phenix.int-evry.fr/jct/。
各会合に大量の書類があり、あり得ないことだが、議長は全てを理解していると思わせる。各会合の meeting reportを頼りに、各提案技術 がどう扱われたかが分かる(*1)。2012年2月(H会合)CD、7月(J会合)J1003 WD9が最終(L1003 WD10)。スケーラビリティのCfPへの提案が2012年 10月K会合に集まった。H.264の文書 ITU-T Rec. H.264(04/2013)は無料入手可能である。検索で出る。完成途中の文書 JVT-G050か、JVT-AF11 の方が理解しやすいが。
画像は一般に空間的に滑らかな変化をするから、空間的な変化は画像をブロックに分割してDCT変換し、少数のDCT係数で符号化表現できる。さらに、 動画像は時間的にも滑らかに変化する。一般的に以前の画像との違いは小さく、画像間の変化が小さい。フレーム間(インターフレーム)予測は、 既に符号化し復号した参照フレームの同位置の対応画素との差分を符号化する。輝度の値は0-255で黒は0白は255とする。座標はx方向は右を正に、 y方向は下を正にする。そして、差分をとると不利な場合は差分しないように、ブロック毎に予測するかどうかをON/OFFする。このON/OFF情報は サイド情報として符号化する。
code(x,y) = Input(x,y) - Ref(x,y) or Input(x,y)
さらに画像の変化を平行移動として、参照画像上で対象ブロックに対応する同位置から動きベクトル (mvx、mvy) だけずれた位置の領域からする 予測を動き補償(MC)という。
code(x,y)= Input(x,y) - Ref(x+mvx,y+mvy) or Input(x,y)
ブロック毎にMC予測するかどうかをブロック毎にON/OFFし、ONのとき必要なフレーム間の動き補償のずれ量、動きベクトルをサイド情報として 符号化伝送する。動きベクトルは整数画素単位(H.261)だけでなく、精度を向上し、元の画素位置にない半画素(MPEG-1,-2)、1/4画素(MPEG-4)、 1/8画素(H.264)の補間位置も取られる。
フレーム間予測をしないブロックはそれ自身で符号化され(H.261,MPEG-1,-2)、インターに対してイントラといい、フレーム間を非イントラともいう。 イントラ符号化には近年大きな技術変化があった。MPEG-4 の "イントラDC-AC予測" は、隣接ブロック間のDCT係数の相関を利用する。DC係数とAC係数 (1次元DCTのDC)を上又は左の隣接ブロックの対応係数から予測する。そして、H.264では既に符号化した隣接画素から方向的な外挿予測する"イントラ予測" が使われる。
フレーム間のMC予測誤差画像のDCTは、予測なしよりはずっと符号化効率を上げるが、元の画像をDCTで符号化できる効率ほどはうまく働かないだろう。 しかし、予測がうまく働かないとき、つまり、シーンチェンジ、影から現れる物体、動きが平行移動以外のとき、物体が変形するとき、フレーム間MC 予測が大きな予測誤差を生むときDCTはうまく働くだろう。つまり、DCTは、MCフレーム間予測のよい補完でありえるのである。
例えば MPEG-1,-2 ではDCT係数はブロック内をジグザグ走査で1次元化され、先行する0の個数(runという)と係数値(levelという)の両方の事象に対応 した2次元VLCで符号化する。変換サイズは、H.261, MPEG-1,-2,-4 まで8画素幅と高さ8のブロック単位でDCT変換する 8x8DCTであったが、H.264 AVC では4x4のブロックのDCT(整数変換)を基本にし8x8を扱わない。16x16ブロックは、各4x4の整数変換とそのDCの4x4アダマール変換との2段階処理にした。
画像の変換は、DCTよりWavelet変換の方がブロック歪がなく高域係数にある局所性がよいとされ、静止画像のJPEG2000で使われたが、動画像でも時間 方向処理(ブロック毎のMCを伴う誤差のWavelet符号化(MCTF))がある。しかし、MCとの親和性がよくないのか動画でのWaveletの優位性は確立していない。
予測は MPEG-1 でB画像を使う双方向予測になり、MPEG-2ではインターレースのためにフレーム/フィールド予測とフレーム/フィールドのDCT型に対応 したが、マクロブロックは、H.264まで続いた。H.264では予測ブロックに小ブロックにする適応性を拡大した。片方向/双方向予測、予測ブロックの 分割(パーティション)を含めたMBタイプをもち、さらにマルチフレーム予測という、2つの参照画像リストL0, L1から MB毎に参照インデックス(参照 画像とMV)を選択して使うことも符号化モードに含められる。
処理方法の複雑化は、どこまで有効であり可能なのかという問いがある。これには、符号化方法を多様化しそれらを区別する情報を与えても、全体と して大きな効果のある方法なら採用するという実証的な判断がされてきた。符号化を標準化するとき、ある方式が例えば符号量の5%の効率向上させる とき、昔は採用されず、現在は採用されるだろう。 符号化は、多くの要素的な個別技術の組合わせ成立しているが、各技術は理解容易な単純さと効率の両立が必要である。個別技術は10%も符号化効率を 上げるものは少ない。例えば、MCは10dB、B画像は20%、半画素精度のMCは5%、VLCはFLCに比べて10%程度の効率向上といわれたが、MVのVLCを改良して 仮に10%削減できても全体には数%までの効果である。また、積み上げられた要素技術は、一度採用されたら変更されないとは考えない。無駄な処理を 削り、複雑な処理を嫌うことは技術の基本である。動画像符号化技術は、どこまでも複雑にして許されるものではない。扱う画像は次第に大きくなる から、単純で大きな効率を与えるものが望まれる。ときに標準化は単純化を行うだろう。ある標準で採用した技術が、次の標準に残ることもあり 消えることもある。
MC予測をするP画像は、同程度の量子化粗さでI画像の約半分の符号量で済む。さらにB画像は量子化を約2倍(MPEG-1 SM3. MPEG-2 TMで1.5倍)に 粗くして画像の符号量を1/4〜1/10程度に減らす。そのため I画像は枚数は少ないが符号量の大きな比率を占める。例えばN=15、M=3の GOP 構造 BBI BBP BBP BBP BBP では、IPBの符号量の比率を 10:5:1 として I画像の符号比率は 25%もある。これを減らすためにGOP構造を周期的にせず、 I画像頻度を下げても、一般にI/P画像の品質は下げずI,P,Bの順に画質を設定する。B画像の画質よりも予測に使うI/P画質を高く設定するつり橋 構造が全体のSNRを持ち上げる。しかし、エンコーダ事項には限界があり、イントラ符号化の改善が望まれた。
5 垂直右 2x-yが0,2,4,6 のとき Pred4x4(x,y)= (p(x-(y>>1)-1,-1) + p(x-(y>>1),-1) + 1)>>1
else 1,3,5 では Pred4x4(x,y)= (p(x-(y>>1)-2,-1) + 2*p(x-(y>>1)-1,-1) + p(x-(y>>2),-1)+ 2)>>1
else -1 では Pred4x4(x,y)= (p(-1,0) + 2*p(-1,-1) + p(0,-1)+ 2)>>2
else -2,-3 では Pred4x4(x,y)= (p(-1,y-1) + 2*p(-1,y-2) + p(-1,y-3)+ 2)>>2
6 水平下 2y-xが0,2,4,6 では Pred4x4(x,y)= (p(-1,y-(x>>1)-1) + p(-1,y-(x>>1)) + 1)>>1
else 1,3,5 では Pred4x4(x,y)= (p(-1,y-(x>>1)-2) + 2*p(-1,y-(x>>1)-1) + p(-1,y-(x>>2))+ 2)>>1
else -1 では Pred4x4(x,y)= (p(-1,0) + 2*p(-1,-1) + p(0,-1)+ 2)>>2
else -2,-3 では Pred4x4(x,y)= (p(x-1,-1) + 2*p(x-2,-1) + p(x-3,-1)+ 2)>>2
7 垂直左 y=0,2では Pred4x4(x,y)= (p(x+(y>>1),-1) + p(x+(y>>1)+1,-1)+ 1)>>1
y=1,3では Pred4x4(x,y)= (p(x+(y>>1),-1) + 2*p(x+(y>>1)+1,-1)+ p(x+(y>>1)+2,-1)+ 2)>>2
8 水平上 if(x+2y==0,2,4)では Pred4x4(x,y)= (p(-1,y+(x>>1)) + p(-1,y+(x>>1)+1)+ 1)>>1
else 1,3では Pred4x4(x,y)= (p(-1,y+(x>>1)) + 2*p(-1,y+(x>>1)+1)+ p(-1,y+(x>>1)+2)+2)>>2
else 5 では Pred4x4(x,y)= (p(-1,2) + 3*p(-1,3)+2)>>2
else >5では Pred4x4(x,y)= p(-1,3)
H.264 のイントラ予測は、JPEG2000より符号化効率が高いことが後に示された。予測誤差は4x4毎に符号化復号される。対象ブロックの予測に隣接 ブロックの復号を使用するブロック直列処理である。画素あたりの予測モード情報は、予測モード推定がうまく働けば小さいが、ブロックサイズ によって違い(4x4に9方向は〜3/16bit/pel、16x16で4方向は 2/256 bit/pel)、その目的も違うようだ。16x16のイントラ予測は背景の平坦領域の 低レート向けテキスチャ再現で、4x4のイントラ予測は、高レート向けテキスチャ再現である。イントラ符号化において、係数空間でなく、 画素空間処理である隣接の画素値の方向外挿予測がDCT係数表現よりも効率的だったのは驚きである。
イントラ予測は、エンコーダが全予測モード(16x16の4種と16個の4x4の9種類全て)を試してモードを選択するので、エンコード処理は重い。また、 隣接の画素を使うのでスライス境界ではモードが制限される。特にスライス先頭MBではDC=128の予測しか使えない。その後の8x8DCTを復活した H.264 FRext拡張で輝度の8x8ブロックにも輝度4x4と同様な9予測モードのイントラ予測が用意され、参照する隣接画素間に(1,2,1)型フィルタを 掛ける。画像の端の画素を延長してMCブロックが画像から出ることを許す無制限MC(Unrestricted MC)のように、一般的に外挿には参照画素間の 低域通過フィルタは有効である。
方向数は、ブロックサイズによって 16x16や32x32は4方向とし、4x4と8x8は方向を増やした。 8x8のブロックの右下隅画素を中心に左隣接16画素 +上隣接16画素の方向(+DC+平面)に依存して、垂直/水平の変換を別にして、予測方向に近い方向をDSTにし他方をDCTにする。さらに、変換方向を 予測方向に合わせる、例えば水平下の方向の予測では左ほど参照画素から遠いが、水平上方向は、逆に右ほど遠いから水平のDSTの方向を逆にする 提案(最終に残ったか未確認)もあった。また、方向的予測モード数を4倍増した分、予測モード推定が当たりにくくなるので予測モードを複数推定 にした。Most Probable Mode MPM_idxを付け、複数候補に当たらない場合に予測モードを符号化する。
提案のなかには 2方向のイントラ予測の平均を使う双予測で、4x4ブロック単位に間を飛ばして実行し、間のブロックは両側から内挿で埋めるイン トラ双方向予測もあった。また、遠くなるにつれてローパスが強くなる画素順次型フィルタなどアイデアは多い。このような外挿予測の最終形は 恐らく部分画像から残りを作り出すN. Wienerの一般調和解析(GHA)であるが、符号化標準にまだ使われない。
我々は波形の一部をみて残りの波形を予想する。例えばある分析区間の標本値の並びは、増加傾向ならそのまま増加の予測をするし、波打つとき 波を続けると予想し、滑らかな連続性を分析区間外との境界に期待するが、それは正弦余弦波形の線形和によって波形を表現することである。 DFTもDCTも任意の波形を滑らかな低域の正弦余弦波形の線形和で表現することができるが、これによって表された区間の外に仮定する波形は、 分析区間の境界に滑らかな連続性を考えるものではない。変換係数を線スペクトルとみるとき、同じ区間波形の繰り返しか鏡像波形になり、 連続スペクトルとみるとき、分析区間は孤立波形である。これらの変換は、波形を完全表現できるが、(例えばDFTでは)分析区間を基本周期とする 周波数の倍数で表わすことがまずいのであり、(但し、DCTはDCの次の係数は、分析区間の4倍の周期であるから問題は少し少ない) 分析区間の外に 滑らかに連続する波形とは一般に分析区間より長い周期の正弦余弦波形であり、これを周期よりも任意に短い区間で分析できないといけない。 GHAは、正弦余弦の2係数を最小2乗法で求め、その正弦余弦波形を除去することを繰り返すが、実際の処理方法は種々可能と思う。
現在のイントラ予測は、画素値の単なる方向的外延である。隣接画素に2-4画素の厚みをもたせる提案もあり、その増減を利用した予測の提案もあった。 これはDCT係数で表すブロックから隣接ブロックを外挿する問題かもしれない。GHAより単純に、16x16の内、右下の1/4の欠けた8x8画像を16x16のDCT 係数から係数をLPFして繰返処理で予測する話もあった。
但し、2次元波形である画像では、波形の濃淡の延長は余り重要でなく、イントラ予測のように隣接画素値そのままの延長で十分かもしれない。 視覚に重要なのはエッジの延長や模様の延長であり、画像内の予測の効果の大半はすでに既存のイントラ予測で得ているかもしれない。波形の 濃淡の延長効果が大きいなら、大きい変換ブロックサイズがRDOによって選択されているはずではないかと反論できるからである。
均一な予測ブロックサイズでなく、分割を必要なときだけする適応的な分割を行う仕組みが必要である。H.263で8x8MCが入った。H.264では様々な 予測のブロックサイズ(16x16,16x8,8x16,8x8)への分割を可能にした。適応的な予測ブロックサイズの決定方法が必要で、さらにMVの効率的表現が 伴う必要があるが、H.264はレート歪最適化(RDO)によって多くの符号化モードからの選択を自動的に行う。
シェイプとテキスチャを符号化するMPEG-4のオブジェクト符号化は、画素単位まで物体の形状に対応したMCである。物体と背景の分離を前提にし、 物体は背景を含めた画像から予測するのではなく物体だけから予測し、背景は背景から形成するようにしたのは、多少の行き過ぎであり、 前提とするエンコーダ側の物体と背景の自動切り分けがまだ可能な技術でないことが問題である。
IDCTの実装を整数演算で規定する H.264の整数変換は好ましい。それまでのIDCTの実装の違いによるIDCTミスマッチ問題の対策が要らない。酷い 誤差を許す激しく量子化された係数の逆変換に、H.261やMPEG-1-2の IDCT の要求する高精度、恐らく20数ビットまでの計算を行い、15ビット以上 の中間結果レジスタの高精度は、単に何も共通化しない標準化の怠慢だった。整数変換にすれば数ビット精度ですむ(*5)。H.264ではこの整数型 IDCTにかけ算さえ排除した。
しかし、HDTV画像の高いレートでは、H.264もMPEG-2も効率が変わらず、逆にH.264に特有のノイズがみえることがあると聞いた。イントラ予測や ダイレクト予測に符号が不足して誤差の量子化が粗いときそれでも普段は、ループ内のデブロックが働いて問題がないが、たまに予測画像の崩れが そのまま現れるのであろう。その崩れ方はそれまでのブロック歪になる崩れ方とは違って、慣れないものだったのだろう。また、H.264はデブロック フィルタをループ内にもつ。ループ外の後処理なら標準が規定しないが、ループ内ではデコーダ必須になるから、初めて聞くとき驚くものである。
8x8DCT(整数変換)の復活追加
4x4 DCTは小画像でのブロック歪や、モスキートノイズ(リンギング)が短いという有効な半面、微細なテクスチャの再現能力は 8x8が4x4よりも
よかった。変換ブロックサイズは、H.264のFRex拡張では、8x8DCT(整数変換)が復活追加された。それに伴って8x8のイントラ予測も追加された。
予測誤差を変換する変換ブロックは、基本的に画素レベルまでの波形再現能力があるDCTが使われるが、大きな変換サイズでは、符号量不足のとき 変換サイズまでの波形のリンギングが出るため、小さく独立した変換ブロックにはリンギングの広がりが小さい利点があるが、小変換サイズは、 変換のパワー集中能力が低いため符号化効率が上がらない。4x4で数個のDCT係数を符号化することが、8x8でやはり数個の係数で表現できるとき、 サイズの違いは4倍まで効率に影響するだろう。
H.264は4x4変換に偏り8x8変換を避けた。予測のサイズをブロック分割し 16x16, 16x8, 8x16, 8x8 にさらに 8x8 ブロックを 8x4、4x8、4x4 に 分割できるが、変換サイズは4x4DCTだけだった。それが FRext では 8x8 DCTを復活し、MPEG-1,-2のような量子化マトリクスを可能にし、4x4DCT と 8x8DCT とを切替え可能にしたが、予測のサイズを超える変換サイズはない。予測ブロック歪を予測ブロック境界を跨ぐ変換が解決するのは難 しい。MC予測境界のブロック歪を変換は容易に消すが、変換内部に来た予測ブロック歪は消すのが難しいからである。

MPEG-4のMCブロックの縦横に2倍の窓関数を重ねるオーバーラップ MC(OBMC)は、オーディオのMDCTのように窓関数を使ってMCブロック歪をなくす 目的の技術であるが、上記理由によってその効果は大きくない。また、MCブロック歪のないことは上下と左右に4重の画像の線形重ね合わせの代償 で成立している。
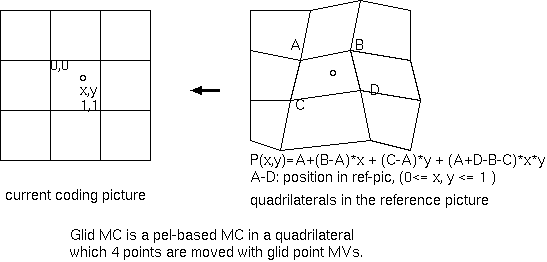
同様に、MPEG-4で提案されたアフィン動き補償予測は、MBのグリッド交差点のMVを伝送し、複雑になりそうなアフィン変換のパラメタをMBあたり 1個のMVで扱う。MC後の正方形のMBが4隅の変位によってどのような四辺形から変形して予測するかを示す。MBの各画素のMVは、4辺形から双線形内挿 (bi-linear interpolation)され、画素値は各画素のMC後画素間内挿で求められる。一般的なブロックの平行移動のMC予測と違って、この予測4辺形 には飛びや重なりがなく画素対応に連続性をもつためMCブロック歪はない。しかし、P6 1MV/MBのアフィン変換は、画素値の内挿が当時の2タップでは LPF過ぎたのかも知れないが、その有効性を明確に示せなかった。MCブロック歪のない原理の異なる方式は、符号量不足のときそのまま見える予測画像 が自然かが問われ、アフィン変換のミスが人物像の異様な変形をみせた。一般に、予測性能向上を目指したMCブロック歪のない技術は、本質的にさほど 必要でなかったのかも知れない。MC-DCTにはMCブロック歪除去能力があるからである。
固定MB、スキップMB
H.261ではFixed(NonMC, NotCoded)MBがあった。TV電話の人物の背景にはそれが多用される。MPEG-1,-2のP画像のスキップMBは、H.261同様の
Fixed MBであるが、B画像のスキップMBは左MBからの動きを踏襲する動きのあるスキップになった。但し、スキップMBはDCT係数も0の非符号化
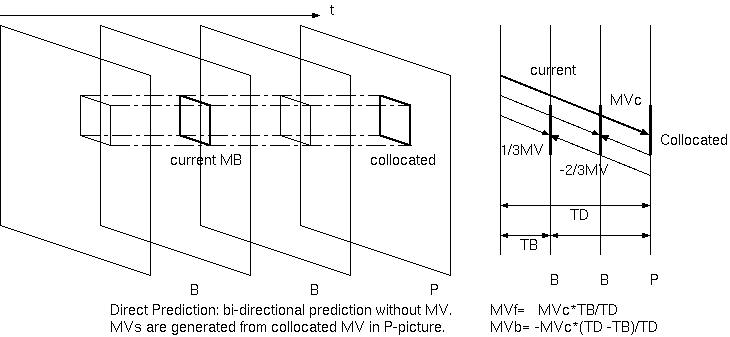
である。MPEG-4ではB画像双方向予測に、最後に符号化したP画像の同一位置のMBのMVを時間方向にスケーリングして用いるダイレクト予測が
見出された。
ダイレクト予測とさらに画像の予測誤差を符号化しないスキップとは、MVの差分(MVD)を付加しない極端な低レート指向の予測である。 予測モードは L0予測、L1予測、双予測が分割された予測サイズに用意されるが、P画像のMVを順逆にスケールしMVDを付加する予測、 片方だけMVを与え順逆に広げる予測はない。H.264ではフレーム間隔による輝度の重み付け予測も明示的と暗黙的との2種を可能にした。 このMV符号量削減技術の流れに、HEVCの動きマージ(スキップ、AMVP)がある。
H.264は、左、上、右上(A,B,C)の3MBのMVがあるとき(2つの16x8への横分割では上はB下はAから、2つの8x16への縦分割では、左はA右はCのMV。 そうでないとき)、A,B,CのMVの成分毎の中央値(Median)によってMVPを与える。成分毎の中央値は、元々存在しないMVを作り出すが、MVDは成分毎 の符号化だから問題ない。さらにHEVCでは、複数候補リストから選ぶ符号を使う選択型MVP(AMVPという)になった。
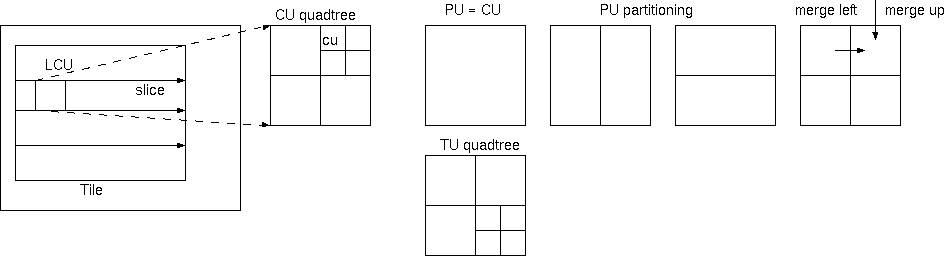
HEVCのクワッドツリー(4分木)型符号化単位(CU)とそれを分割するPU(予測単位)とTU(変換単位)は、平坦な部分に大きな符号化単位を残すことによる 低レート化と、画像の微細な部分には自動的に小さなCUを対応させる。このとき、分割が自由になるに代わりに複雑になるPUのMVの効率的表現が必要 になる。そこに動きマージがHEVCの初期から提案され、上か左のPUに動きを合わせるmerge_flagと左/上のいずれかを示すmerge_leftフラグであったが、 最終的には最大5候補リストからの選択の merge_idx になった。AMVPの扱いも類似方法になり、空間隣接から候補を追加し、時間隣接からも追加する 最大2候補からの選択である。このとき隣接からのMVは使用するフレーム間隔にスケーリングされる。時間隣接からのMVP(TMVP)は、効率向上に有効だ が伝送エラーに弱く、これを強くしデコーダの符号解読(パース)をデコーダ動作から独立させるために、候補数を一定にして、重複ベクトル削除、 ゼロベクトル追加する。画像毎にTMVP使用/不使用フラグを記述し、数フレーム毎に全くTMVPを使用しない画像にして伝送エラー伝搬をさける。
スキップ/動きマージ/動きベクトル予測(AMVP)の3つは、いずれもイントラ予測モードの推定MPM_idxのような複数候補リストからの選択符号を与える 選択型である。スキップは、動き差0、DCT係数も0。動きマージは動き差(MVD)が0だがDCT係数を符号化する。AMVPは、予測ベクトルを選択して差分MV (MVD)を符号化する。期待された高効率符号化(HEVC)は、このような4分木構造と動きマージの組み合わせだった。これがHEVCの効率向上の主要点だろう。
H.261ではGOB(Group of Block 11x3MB) を使ってCIFは2x5GOBだった。MPEG-1でスライスが、Philips提案で画像フォーマットを自由にさせるとして H.261のGOBの代わりに導入され、任意サイズ(横幅〜4095)の画像を扱えるようにした。MPEG-2は横16k画素のサイズまでを扱う。GOBと比べてマクロ ブロック幅のスライスの細長さに心配はあったが、スライス内で値を引き継ぐものは quant とイントラDCとMVである。MPEG-1,-2ではquantはスライス 先頭でsquantで設定し次々のmquantで変更しながら継続する。イントラDC予測とMVPも1次元で左隣接のMBの値を引き継ぎ、上隣接の情報を利用しなか った。それゆえスライス外を使用しない効率低下の認識がなかった。また、MPEG-2のMP@MLではスライスは1行の中に限定され、同一スライスのMBが 上下に並ばないため上隣接を考慮しなかった。言い訳である。
MPEG-1,-2標準は逆量子化を決め、量子化はエンコーダ事項であり自由である。エンコーダは、内部に正確なデコーダをもつ必要があるが、DCT係数 の大きさが符号量に影響するからたまに発生する大きな係数を小さく符号化するような、量子化と逆量子化を違えることもできる。これは大抵、頑丈 さのためである。QMも変化できる。また、MPEG-1,-2ではイントラと非イントラで逆量子化が異なり、非イントラACは0から離して再現される。逆量子化 のイントラACはlevel*mquant*QM/16 で再現し、非イントラは、(level+0.5)*mquant*QM/16 で再現する(*6)。逆量子化に対応する量子化、代表値が 重心からずれないエンコーダ側の量子化は 16*coeff/(mquant*QM) の割算"/"には、イントラで丸め付き、非イントラで丸めなしが対応するのである。
Eij= Σ(rijQij-Sij)^2
dEij/dQij= 2Σrij(rijQij-Sij)= 0
Qijopt= Σrijsij/Σrij^2
これとは別に、ブロック境界画素への影響度から、高域を粗く量子化する理由付けがある。DCT係数それぞれのブロック境界画素への貢献度は高域 ほど小さい。Qijを、その逆数に比例させればよいのである。
EG0符号は、0から始まる整数(又は1から始まる自然数)を 0, 01x, 001xx, 0001xxx, ... (x=0/1)によって表す。(EGk 符号は、EGの前置数 + k bitの後置を使う。k=1 なら 0x, 01xx, 001xxx, 0001xxxx、k=2 なら 0xx, 01xxx, 001xxxx。) 2進化を工夫して短い符号にして算術 符号化のbin数を減らし、かつ bin 毎も重い context を削減し、bypass (50%確率)比率を高める。これはCABACの処理の重さが原因である。
VLCテーブルの約2倍拡張
H.261からMPEG-1へDCT係数のVLCテーブルを約2倍の大きさにした効果は小さく、私の測定では +0.06dB だった。しかし、ハードウエアの
作成可能性の向上に合わせて符号化のしくみを多少複雑にするのは時代の流れであるが、VLCの設計は規則的VLCよりよいなら正当性がある。
CBP
符号化ブロックパターンのVLC。これによって、空ブロックがないことを利用した仕組み、ブロックの最初の係数にEOBは来ないから2DVLC
の最初のVLCだけEOBと重なった符号が使われる。このCBPの有効性に疑いが残るが、H.261とのコンパティビリティが優先された。
CBPを無くすには2次元VLCの作り直しが必要になるからである。
B画像は誰もが有効性を認める仕組みであり、実際に2dBというB画像の効率向上は、それまでもそれ以降もその他のどの個別技術よりも効率に貢献 した。MPEG-2のDual prime は M>1 では1dB以下だったから採用されず、M=1では 1dBを超えていたから採用された。単一の道具による+2dBもの 効率向上はB画像以外みない。にも関わらず、B画像は画像の符号化順が元の画像順と異なるので遅延を生む。しばしばB画像は不要と疑われ、通信の 低遅延には、2つの順方向を平均する予測なら遅延は増えないことがあり、MPEG-2の標準化過程でB画像の有効性は疑われたが、B画像を結局超えられ なかった。MPEG-4もこれを踏襲し、H.264はマルチフレーム予測、双予測として方向を限定しない2つのL0, L1の参照画像リスト中からMB又はサブ ブロック毎に参照画像を多数の画像から選択させ、重み付け予測も導入したが、2画像の平均は変わらない。3,4画像からの予測を同時に使用しない。
MPEG-1の半画素MCは、MPEG-4では1/4画素MCとなる。H.264では1/8画素単位の画素補間と発展した。これは画素の必要な精度でもあり、平均化のもつ 偉大な符号化効率でもある。MPEG-1で双方向予測を時間間隔による重み付けさせる必要は殆どなく単なる平均にしたことも、同様な意味をもつ。 単純平均はフィルタ付き予測の効果によって、フレーム間隔に応じた重み付け予測の優位性を小さくするからである。
双方向予測は、重み付け予測から、単純平均になった
フレーム間隔の逆数による重み付け予測はほとんど効果がないと確認したというNECの太田睦氏の発言で、MPEG-1のSM2からSM3の間で、双方向予測
のフレーム間隔による輝度への重み付け係数を両方固定の1/2にして平均にした。当時、単純化(Simplicity)をも評価基準に挙げていた。
I/P/B画像
なぜ全てをB型にしないのかという疑問が当時からあった。特にP画像は、H.261の画像型である。B画像の双方向予測はそれより予測が格段によい。
B画像でも全MBをイントラや、片方向予測にでき、I/P画像の代わりにした場合の効率低下は大きくない。I/P画像にそれ専用のMB型を持たせる必要は
効率上殆どない。そうすれば MPEG-1ですでに、H.264 のマルチフレーム予測になっていたのではないかという思いがある。
しかし当時、ピクチャタイプは、画像の予測構造を決める唯一の情報だった。Iは独立に符号化され、Pは他のI/P画像から予測し、Bは、I/Pから予測 する。そしてP画像のMBタイプのように既成の標準とのコンパティビリティ要求があった。P画像はQM=16にするとH.261画像からの変換が可能と 思われていた。
コンパティビリティは徐々に不可能になっていた。B画像はそれを使わなければよい。量子化マトリクスは平坦な設定をすればよい。GOBがスライスに 変わる。逆量子化を違える。ループ内フィルタがない。MVの半画素単位、F_CODEによるMV表現、符号化効率上必要なものは、コンパティビリティには 邪魔だった。それらによって、コンパティビリティが保てないことに、我々は徐々に気が付いていった。そして、コンパティビリティを求める通信系 の人々は、使用者の利便を標榜するが、技術の変更に保守的にさせるのは、じつは、技術の所有者の利得であった。
H.261を作成してきた通信の人々は、できる限りのコンパティビリティを望む。NonMC coded のようなMB型と逆量子化をH.261に一致させ、B画像の スキップがそれを超えるとは考えなかった。すでにH.261からMPEG-1 に変わって、双方向予測のために参照画像メモリが2倍に増えていた。これを 2段階双方向のために画像型を増やすことは、CIF画面のサイズのフレームメモリがさらに1枚必要になり、現在からみると馬鹿げているが、それは 致命的に思われた。まして、画像型を無くすことは殆ど考えが尽きてしまう。
しかし、当時の「2段階双方向」という概念も限界をもっていた。H.264のマルチフレーム予測は、参照画像をL0,L1という参照画像リストからMB毎に 選択し、どの画像型もB画像さえ何枚も参照に利用する、フレーム構造を超えた効率優先の仕組みにした。ただ、HEVCのHMのランダムアクセス画像で は階層的に量子化を違えた2段階双方向や3段階双方向の画像構造を採り、それを時間的階層という。NAL unit headerには、temporal_id が記述され、 パケット毎に時間的階層を分離できる。
1つの予測に同時に使用するのは2枚までであり双予測という。3枚以上の平均を使えば予測性能はまだ向上するかもしれない。この手の予想は、効果 を確認し最適化して初めて実証される。試し実用にするまでにはエンジニアリングがある。誰もが結果を予想して実験を開始するが、正しかったかは、 実験者がプログラムし全てのバグを取り去った後知ることである。そして、大半の予想は間違ってきた。最大のバグはそれが有効という予想自体だっ たりする。ひとつの道具ができるとき、その数十倍の道具が生まれ消えていくのである。
MPEG-2インタレース符号化では私はスキャンの切替え(zigzag/vertical)を提案して、量子化グループで、run-level 2次元 VLCを run, level 個別符号化で、しかも単純なWyle符号(今ならEG0(Exp-Golomb, k=0)という)で、それぞれ符号化したほうが却ってよいSNRを与える ことを知った。つまりMPEG-1,-2の 2次元VLCはよく調整されていない。その後、MPEG-4 標準化のなかで Universal VLC(UVLC) が主張された。 そのような規則的VLCでよいなら大規模なVLCよりその方が単純である。VLCは統計から設計するが、熟慮されていない設計は無意味である。 但し、DCT係数の符号化は、全体に最も大きな影響を与えるから、最大の注意が払われるべきである。
H.264以降は、最大頻度の符号は、係数の有意性(非0)の符号であるという。HEVCでは最後の係数位置とともに、16x16以上は4x4サブブロック(SB) 有意性を符号化して、隣接SB有意によるSB内部の係数位置によるコンテキストを使って係数位置の有意性を符号化する。H.264では絶対値-1と 正負符号だったレベルは、絶対値-1, 絶対値-2, 絶対値-3と正負符号で符号化する。
MPEG-4は、オブジェクトベースの符号化という、シェイプ(形状)とテクスチャ(模様)による機能性を追求した符号化標準である。形状の符号と 模様の符号化であるが、形状周辺で2次元DCTの正方形が5角形や3角形になる対応をするshape-adaptiveDCT(SA-DCT)によるテクスチャ符号をもった 物体を符号化し、別に符号化した背景の前を運動させる、2次元オブジェクトである。背景の符号化も、最初から背景をできるだけ広く与える スタティック・スプライト、隠れた部分が再度表れることを利用したダイナミック・スプライトが技術があった。それらは高いプロファイルに 置かれたが、使われたのだろうか。効率にまさる機能性などなかったのではないだろうか。
JPEG-2000は、変換に Discrete Wavelet変換(DWT) を使いブロック歪みなく、JPEGの2倍の効率の符号化にしたというが、ここ10年間JPEGベース ラインの単純さに勝てなかったのではないか。そして、H.264のイントラ予測が JPEG2000 よりも効率が高いことが示された。符号化は、 より効率的な符号化によって淘汰されるものである。
MPEG-4 のスーパーマクロブロックは MPEG-2のマクロブロックMB内部で済んでいたフレーム/フィールド予測とDCTtypeの構造を崩し、MB層の 外側に影響を広げ、フレーム画像に上下に並ぶスライスのMB正方形を関連づける必要をもち、フレームの正方MBを崩す利点はなかったと思う。 MPEG-4 は、インターレース符号化ではMPEG-2よりも後退させただろう。放送用途など高品質な用途を考えない低レートでは起こりえることである。
平行移動とアフィン変換、GMC、グリッド内挿MC、ダイナミック・スプライト
画像からのオブジェクトの切出しは、簡単でなく成功していない。動きによって奥行きを知るのは、「不完全設定問題」である。
画像の部分的動きの大きさは、物体の表面模様の近さを表す。オクルージョンによって立体構造を知るようなことをしないと、単に
オクリュージョンがあるからMCが当たらないといつまでも言い訳をいうことになる。MPEG-1の双方向予測は、隠れた背景の現れ
(uncovered background)の予測を可能にしたが。画面内の動きが平行移動でないのは、実際に物体が不均一な動きをするときもあるが、
剛体なら動きの大小から、物体の奥行きを求めることもできる。しかし、動きの原因が平行移動か回転か変形かは知ることができない。
平行移動の動きベクトル以外、多くのパラメタをもつ2次元のアフィンマッピングを効率的に表現するブロック交差点(グリッド点)の 動きのブロック画素への内挿がMPEG-4で議論された。画像全体の4隅の動きで画面のアフィン変換を扱うグローバルMC(GMC)もパニング などによいが、グリッドMCはさらに既存の動き表現に互換性をもち、ブロック内の物体の変形を表現できる。符号化効率のよい証拠が 十分なかったからだろう、残念ながら標準に入らなかった。符号化の道具として単純で美しく有効そうに思えた。 それでも、MPEG-4は波形ベースでなく、モデルベースの符号化に一歩踏み出し、背景のスプライトによる形成、隠れていた背景が現れる 度に背景画像に修正追加するダイナミック・スプライトなど、それが可能であることを示した点を評価すべきであろう。
しかし、H.264 の目的にした高能率符号化は、将来にも残るだろうと好意的に受け止められる。現在、H.264で必要なものはエンコーダ の選択と単純化である。余りに複雑なために使われない道具立てやRD最適化は、将来可能な計算量によって実用になると計算量は正当化 しても、細々した複雑な仕組みは違うのであり、効果の少なかった道具類の整頓は必要かと思うと、ソフトウエアならあまり整頓の必要 もなく、整頓もエンコーダ事項かもしれない。しかし、次の標準HEVCにその技術のほとんどが引継がれ継承され拡張されたことが技術の 正しい方向を指していたといえるのではないか。
しかし、HEVCが本当にH.264の2倍の符号化効率、MPEG-2の4倍の符号化効率とは思わない。H.264の3,4割増し程度の符号量に対応するという 性能報告が終盤にあった。CABACとRDOはすでにH.264で使われていて効率増加にならない。H.264もRDOを除去すればMPEG-2の1.5倍程度まで であり、2倍というのはRDOによる複雑なエンコーダに頼った性能である。MPEG-2はMPEG-1に比べてインターレースで2割の圧縮性能向上という 大変控えめな性能評価をMPEG-1,-2のVideoの議長のLe Galは行ったが、それに比べてH.264とHEVCは、大変几帳面な決断の連続を記録に残す 議長の、符号化標準性能の宣伝文句である。そのような複雑なエンコーダを使えば MPEG-1, -2にも1.5倍〜2倍程度の符号化効率の向上は容易 といえるし、MPEGはデコード処理とストリームシンタックスの標準化であって、将来のためにエンコーダ事項を標準化しないのであるから、 エンコーダによる性能は、符号化標準の性能とは、切り分ける必要がある。
HEVCではCABACの算術符号化の部分の代用の提案がいくつかあった。例えばV2Vという可変長から可変長への変換によるものである。 CAVLCとともにそれらは全て消えたが、元もと効率優先よりも処理削減優先の技術は中途半端であった。しかし、2値化で2進符号にして 0/1比率の偏った短い符号を作れば、それを自動的に50%の符号にまで短縮する方法は文脈に依らずとも可能だろう。HEVCの後半では コンテキスト削減とバイパス化とその纏めに力を尽くし、コンテキストはH.264の数分の1にした。
上述したが、H.264のイントラ方向性予測は、符号化対象ブロックの隣接画素からの多くの方向の外挿予測の選択で、上、左、DC、.... と 9種の予測方向をもつ。16x16 と間が飛んで 4x4 しか無かった。各ブロックにその選択の符号が使われる。16x16にはたった4種であり、 Highレベル用の Fedelity Range Extension では 8x8 DCT が復活したと同時に、イントラ予測にLPF(121型) フィルタ付き 8x8 が用意された。 このような模様の周辺からの方向予測、一種の空間的DPCM予測の有効性はどの程度だろうか。どこまで発展しうるのだろうか。
イントラ MC
画像内の動き補償、イントラのブロックコピー、イントラ画像内の上や左にずれた位置からMC予測するイントラMCはまだ標準外である。HEVCへの
Renesas提案(JCTVC-A126)は、現在ブロックと予測ブロックの重複部分で2MVの位置の画素を使うようにした。HEVCのRExtではイントラMCが再登場し、
ディスプレイ画像の符号化、ロスレスなど高画質で効果の大きさが認識された。今度は標準の道具になるかもしれない。画素が重複するコピーは
処理順によるが、 (重複領域の扱いかたをスキャン順の画素処理とすると、)方向的外挿予測になる。例えば(-1、-1)のMVを使うイントラMCは、
左上の隣接画素からのイントラ予測になる。(0,-1)は上から、(-1,0)は左から、(1,-1)は右上からである。提案(JCTVC-F617)のようにMV精度を
1/2画素にすると、角度分解能(45度)が倍になり、H.264の4x4と同じく8方向からのイントラ予測類似になる。しかも、画素延長だけでなく、
繰り返し模様を再現できる。例えば(-2,-2)とすると2画素幅の左上からの模様の繰り返し延長になる。イントラ予測は余りに細々とした繁雑
な処理であり、このイントラ予測を包含したイントラMCに単純化できるかもしれない。
使用頻度順位列による符号化
数十年前、神奈川大学の小松先生はエンコーダとデコーダで同時に使用頻度を直接に計測しながら可変長符号の割り当ての変更を研究された。
ベクトル量子化のコード使用順においてVLCを割り当て、使用頻度の順を非零係数ごとに累積し頻度が逆転すると1つ前と交代する。同時にVLCも
交代し変更する。この順序列は係数の可変長符号化(VLC)においても、可変長符号の適応性を確保するのに有効であろう。また、使用順位にVLC
を割り当てる問題だけではなく、この順位列適応は、係数位置の符号化又は走査順の自動化においても有効であろう。
順位変更は、使用頻度表をもって直前の候補と交代する方法以外にも、使用頻度表を持たずに、非零係数発生において直前の零係数位置と交代 するという方法もある。これは順位自体が過去の確率の結果に適応することを利用する。先頭に移動(Move to Front MTF) という方法もある。 Nだけ前に移動という方法もある。さらには、Tree状になったVLCで表される各シンボルが使用頻度をもち、符号の使用によって、Tree 構造を 変更する必要が出たときに変更すれば行える。これは Dynamic Huffman という方法である。しかし、VLCではどのようにしてもCABACには 勝てないだろう。
(*2) つまり、外挿予測もDSTも古い技術で、JPEG、MPEG-1の頃に欲しかった技術だが、そんなことは決してできなかっただろう。 当時のシミュレーションではあの単純なMPEG-1のSIF、MPEG-2のSDTVの1フレーム処理するのに数10秒から1分もかかった。
デコードしてリアルタイム表示は、MPEG-1 のときワークステーションでも不可能だった。SIFの30Hzデコード表示は、かなり後である。 それゆえ、道具を考案してもプログラムする労力がいる。そしてテストすることは難しい。多くの画像でテストして初めてその道具が役立つか どうかが分かる。そのような道具を10個ぐらい考えて作り、組み合わせて初めて提案に参加できるのである。これは会社がサポートしてくれて 直前にチームを組んでくれても才能がある後輩に恵まれることは稀で、才能ある先輩はもっと稀である。才能ある若手は批判はするが手助けは しないだろう。ほとんど全て自分一人でやることになる。それを覚悟して初めてできる作業である。提案はきつかったし、提案の書類を作った ワークステーションはHDDがクラッシュする。他社からの社員は巧言をいって私から技術を聞き出して特許を書いていた。それはずいぶん後にな って知った。そして、標準化で知り合った人々も私の技術を聞いて色を変えたときは、大抵あとでその人が私のアイデアを使って特許を書いた ことを知るのである。私も特許は要求されるがそれさえ一人の作業になってのしかかる。先輩は要求するが技術的内容を知らないので肩代りし てくれるはずもない。そこで私は特許だけは放棄して技術者の成果から抜け落ち、そして論文を書くことも放棄して名誉から抜け落ちることを 選ぶ。両方とも自分だけが我慢すればすむことだからである。少なくとも誰かを傷つけることはない。そして、自分から求めた苦労だけは自分 を救うことを知る。
現実にプログラムを書き最適化しデバッグする人的労力に限界があり、10本程度の標準画像各5秒をテストするには一晩かかるという計算機 パワーの限界がある。当時不可能だった高度な最適化処理が徐々に可能になっていく。そしてそれは現在も量的な違いはあっても同様な限界 があると考えざるを得ない。符号化の技術は、とくに画像は、扱う画素数が多いために単純なことしかできない。画像は右から左に移すだけ でも重たい。
(*3) MPEG-1からMPEG-2まで、シミュレーションモデル、テストモデルは仕様だけで、プログラムは参加各社がそれぞれ作成した。共通ソフト がないので結果の出る速度は遅かった。B-quant は、TCE の Tristan Savatierによって主張され、私の反対で消えた。実験結果なしの道具 追加は許されないことと、符号設計もだめだった。
(*4) F_CODEは、動きの分布を知る符号化前にその最大の大きさを決める必要があるという不都合がある。大抵の動き検出には最大動きの制限 があり、それを画像間隔に応じて設定することで事足りるが、MVDに拡張可能な規則的なVLCを使えばどこまでも伸びるMCは容易に実現できる。 MPEG-2で私は動きベクトル差分MVDの符号化にはF_CODEでなく、Wyle符号を使い制限なく拡張できることを示した。殆ど全ての標準画像で結果 が良かったが、特別に動きの大きいCG画像、Confetti(紙吹雪)で結果はF_CODEに負け、採用されなかった。
(*5) 私が MPEG-2の終了近い時期にPCSとMPEGに、3.5bit精度の整数型DCTを発表したとき、IBMはすでに興味をもって研究していたことを知り、 同じ時期にNECの宮本さんが、同じ係数を独立に発表したことに驚いたものである。これによって低下するSNRは、0.1dB未満だから採用されれ ば利点が大だっただろう。
(*6) このときの"/16"に、私は、逆量子化に+8の丸めが不要で、量子化側の対応も必要がない結果を示し、確率分布を理由にもつとし、逆量子化 の丸めを省略させた。