図 1 422 と 420
トリケップス出版 "MPEG 技術" (White series No.152)の Video部分(pp.29-127))の
1993 年 12 月 21 日出版の原稿である。
1〜9章は MPEG-1 Video、10〜21章が、MPEG-2 Video の技術的解説である。
この文章は、MPEG-2 の CD 通過時点の技術的内容であり、当時までの数年間の MPEG 標準化活動 に参加しつつ雑誌"インターフェース" に書いた技術報告をまとめ加筆したものである。 トリケップス出版のこの本は、高価な企業向けの本で 200 数十部しか出なかったと聞いている。 監修はSonyの米満潤氏、オーディオはJVCの杉山昭彦氏、システムはNECの松本英博氏が担当された。 MPEG を仕事にする技術者に有益な本で、私には私以外の部分が後年、非常に役立だった。 今回、私の部分を HTML にして公開するのは、Internet を読書の場所にして欲しいからである。 加筆訂正は、敢えてほとんど行なっていない。
ISO の正式文書は、IS11172-2 が MPEG-1 であり、IS 13818-2 が MPEG-2 であり、これらはつねに 入手可能である。また、その後 IS までの修正については他の文章を参考にすべきである。 私を含めたこの数人は、1993 年 5 月から JIS 化の作業に関わった。MPEG-1,-2 の全体のまとめを NTTの渡辺裕氏にお願いし、私は、Video の JIS 策定の主査をした。 MPEG-1 では必須部分は全訳、参考部分は抄訳なので、10 人の MPEG の画像符号化技術の専門家が参加した。 MPEG-2 は抄訳である。国内では、これらの国際標準に対応する日本工業規格 JIS X 4322 と JIS X 4356 が 法律に準じる規格として国際標準に優先することに留意されたい。
1. 動画像符号化の基礎技術
2. 動画像データ
2.1 422 と 420
2.2 フィールド画像とフレーム画像
2.3 CIF と SIF
3. フレーム間予測 と 動き補償(MC)
3.1 マクロブロック
4. DCT (Discrete Cosine Transform)
4.1 1次元 DCT
4.2 2次元 DCT
5.シーケンスヘッダ と GOP
5.1 双方向予測
5.2 処理順、メディア上の順
5.3 GOP の独立性、編集性
5.4 ハーフペル MC
5.5フレーム間隔と動きベクトル
5.6 スライス
6. ブロックとマクロブロック
6.1 マクロブロックアドレス (MBA)
6.2 マクロブロックタイプ
6.3 動きベクトルの差分符号化
6.4 マクロブロックパターン (Coded Block Pattern)
7. 量子化と逆量子化
7.1 量子化マトリックス
7.2 DC 予測
7.3 ジグザグスキャン(走査)と 2 次元 VLC による係数の符号化
7.4 IDCT ミスマッチ対策
7.5 MPEG デコーダの構造
8. 標準化の外の基礎技術
8.1 動きベクトル検出(MVD)
8.2 レートコントロールと符号化制御
8.3 その他の標準化外の技術
9. MPEG-1 のシンタクス補足
9.1 スタートコード
9.2 シーケンスヘッダ
9.3 GOP レイヤ
9.4 ピクチャレイヤ
9.5 スライスレイヤ
9.6 マクロブロックレイヤ
9.7ブロックレイヤ
10. MPEG-2 Main プロファイル技術
10.1 MPEG-1 から MPEG-2 への経過
10.2 MPEG のフレーム構造から MPEG-2 のフィールド構造へ
10.3 久里浜会合での主観評価
10.4 32 社の提案アルゴリズムから思うこと
11. シンガポール会合の結果 TM0
11.1 TM0 の 422 to 420
11.2 TM0 の レートコントロール
11.3 Frame/field 予測
11.4 Frame/field DCT
12. Haifa 会合の TM1、FAMC と Dual field
12.1 MPEG-2 の スケジュール
12.2 Haifa 会合での種々の問題
12.3 予測以外について
12.4 10 Mb/s 問題
12.5 10 kb/s 程度
12.6 Loss Less Coding
13. Haifa 会合での 3 つの問題に対するリオ会合での各国の解答
13.1 10 Mb/s 問題
13.2 10 kb/s 程度
13.3 Loss Less Coding
14. TM2 の Frame-picture, Field-picture
14.1 MV 表現
14.2 422, 444 の CBP の改良
14.3 予測の Core Experiment
14.4 量子化などの Experiment
15. ATV 技術の登場
15.1 予測関連技術
15.2 量子化関連技術
15.3 MPEG-1 の IS 化に伴う動き
15.4 ソフトウエアデコーダ
16. 8 点 DCT 高速アルゴリズム
17. プロファイルとレベル
17.1 コンパティビリティとスケーラビリティ
17.2 スケーラビリティ
17.3 ローディレイ
17.4 ハイレベル
18. Main プロファイルのシンタックス
18.1 Main プロファイルの予測構造
18.2 フレームピクチャ、フィールドピクチャ
18.3 参照フィールドのルール
18.4 予測(MC)の種類
18.5 動きベクトル表現
18.6 Dual prime
18.7 DCT type
18.8 ハイクオリティ対応
18.9 Alternate Scan
18.10 IDCT ミスマッチ対策
18.11 エラーレジリアンス
18.12 PMV
18.13 TR
19. ATV の 大同盟 G.A.(Grand Alliance) と MPEG
20. ニューヨーク会合、ブリュッセル会合、ソウル会合
20.1 プロファイルとレベルの議論の推移
20.2 ビデオの変遷
20.3 MPEG-4
20.4 ベリフィケーションテスト
20.5 MPEG-1 の出版
20.6 ATV の MPEG-2 Main プロファイル High レベルの採用
21. Main プロファイルのシンタクス補足
21.1 Sequence extension
21.2 Sequence display extension
21.3 Quant matrix extension
21.4 Picture coding extension
21.5 Picture display extension
参考文献
動画像の符号化にも静止画符号化の技術を利用してもよい。しかし、それでは 符号化は非効率になる。動画像は人間の目でみられるだけの安定性があって、 1 枚 1 枚の画像が全く違うものはすでに動画像ではない。 (画像が 全く一致するものも動画像ではないが。) 動画像の多くの部分は絵の類似性があるはずで、それを利用する符号化が 必要になる。これがフレーム間予測、 MC (動き補償) という技術である。
つまり、符号化 (coding) というのはアナログをアナログとして帯域圧縮する のではなく、ディジタルをディジタルとしてデータ圧縮するのでもなく、 ディジタルにする段階で、アナログの画像の性質を利用した効率的表現をする 技術である。なめらかな画像を少数の係数で表す変換符号化 DCT (Discrete Cosine Transform)はこうした理由で存在する。
これより、動画像符号化に使われる基礎技術を紹介する。純粋に画像符号化 としての技術と、蓄積メディア用の機能的に必要なものだけにして、文法のみ に関係するものは、できるだけ簡潔に記述することにした。 それらは本質的なものでなく、決め事でしかないからである。 まず画像データについて説明し、純粋に画像符号化として必要な技術で、 最も重要である、MC と DCT について説明する。
画像が白黒の場合は このような輝度画像のみで十分であるが、 カラー画像は RGB の 3 つの値または 3 つの画像で表される。これを次のように線形変換して、 輝度(Y)と 2 つの色差(Cb,Cr)で表わすと、色差画像の空間分解能を減らすこと ができる。下式の y,u,v にあたる値が符号化の処理をうける 3 つの 8 bit 値である(SMPTE 170M から) 。 なお、R,G,B はすでにガンマ特性という、光電変換時の非線形(0.45乗)特性を受けている。
V= 1.099 L_c^{0.45}-0.099 ( for 1 >= L_c >= 0.018 )
V= 4.500 L_c ( for 0.018 > L_c >= 0 )
r = R/255.0, g = G/255.0, b = B/255.0
Y = 0.299 * r + 0.587 * g + 0.114 * b
Cb = 0.564 * (b - Y)= -0.1686 * r - 0.3311 * g + 0.4997 * b
Cr = 0.713 * (r - Y)= 0.4998 * r - 0.4185 * g - 0.0813 * b
y = 219.0 * Y+16, u = 224.0*Cb+128, v = 224.0*Cr+128
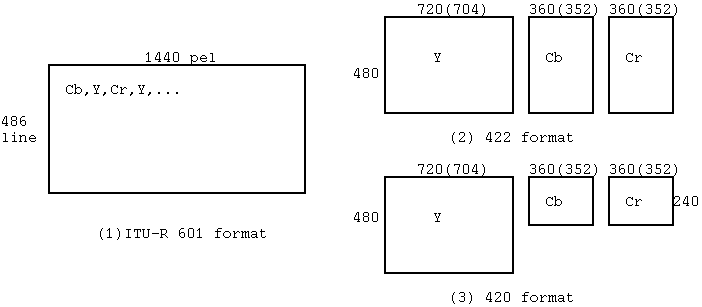
これから Y, Cb, Cr を拾い集めて画像としてみると、その輝度画像は 720 x 486 の大きさで、 2 つの色差画像は横方向にサブサンプル(間引き)された 各 360 x 486 の縦長な形をしている。
420 というのは 422 に対していう言葉で色差をさらに縦方向にもサブサンプルした 画像形式をいう。色差画像の大きさは縦横とも輝度画像の1/2 になる。 これがもっとも一般的に動画像符号化で使われる形式である。 420 では、輝度画像 (Y) と縦横比の一致した 2 つの色差画像 (Cb,Cr) がセットになって扱われる。
それに対して、MPEG では特定のピクチャフォーマットはなく、 1 画素単位で 4096 まで、画像サイズは自由に設定できる。 MPEG で、SIF ( Source Input Format )というものが 単にシミュレーション用に作られたが、これは画像形式を標準が定めたわけ ではないので注意する必要がある。
SIF は NTSC 圏では 360 x 240 x 30 Hz( 内 352 x 240 を符号化。 色差は176 x 120) PAL 圏では 360 x 288 x 25Hz ( 内、352 x 288 を符号化。)である。両者は 画素レート (毎秒の画素数) は等しい(図 2 )。
なお、 MPEG-1 のシーケンスヘッダに記述される、制約パラメータフラグは CIF 画像までの面積以内である事等の 9 つの条件を満たすフラグとしている。 そのため、すべての制約パラメータフラグの立っているビットストリームを デコードするためには、CIF 画像の大きさ、SIF 画素レートのデコードが デコーダ能力の目安である。

入力画像どうしの差分でなく、以前の再生画像を引き算することに注意されたい。 再生画像との差分であるから、入力画像を知らない、遠方のデコーダが次の再生画像 を作ることができるのである。
エンコーダのなかで、再生画像を引き算するためには、エンコーダの中に デコーダ(ローカルデコーダという。)を持ち、再生画像をつくる必要がある。 エンコーダとデコーダの 2 つの再生画像は一致するのが原則であり、 この原則が満たされない時は大きな問題となる。
動画像のほとんどの領域は以前の画像と近似し、 差分(フレーム間予測誤差)のパワーは一般に、 もとの入力画像のパワーより小さいため、 フレーム間予測は有効で符号化効率を向上させる。
さらには、各ブロックに参照画像の対応位置からのずれ量を示す"動きベクトル" を用意し、以前の再生画像から動きベクトルだけずらした所から予測する フレーム間予測を動き補償 (Motion Compensation) という(図 4)。 予測誤差パワーを減少させる効果、は一般に単純フレーム 間予測より大きい。動きベクトル情報もブロックの付加情報として送られる。
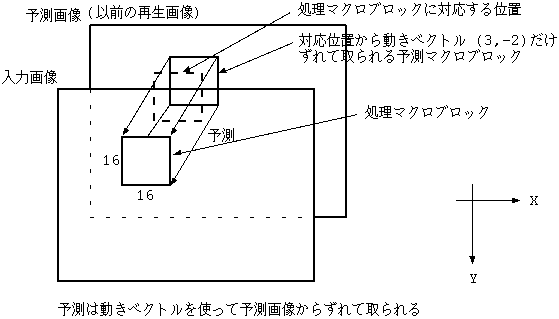
また、付加情報である動きベクトルの符号量は MC による中身(予測誤差)の符号量 減少からみて普通問題にならない。色差画像では、一般に輝度画像と比べて大きさ で 1/2 にされているので、動きベクトルを 2 で割って同様な MC を行なう。
動きベクトルを求める処理(動きベクトル検出)はエンコーダ側の処理であり、 標準の外の処理となるが、これについては後述する。
difference_{i,j,k}= { input_{i,j,k} - reconstruct_{i+mvx,j+mvy,k-1} ( inter )
input_{i,j,k} ( intra )
ここで、 i,j を画素の添字、k を画面の添字とし、difference_{i,j,k} は 符号化する画像、 input_{i,j,k} は入力画像、reconstruct_{i,j,k-1} は以前の 再生画像。(mvx, mvy) を動きベクトルという。
DCT は画像信号を少ない低域係数に集中させる働きを持ち、画像の空間的方向の 情報量削減に使われている。DCT は固定の変換係数の直交変換のなかでは 画像符号化に最も有効な変換とされている。
X_k = √(2/N)C(k)Σ_{i=0}^{N-1} x_i cos(πk(2i+1)/(2N))
x_i = √(2/N)Σ_{k=0}^{N-1}C(k) X_k cos(πk(2i+1)/(2N))
ただし、
C(n) = { 1/√2 (n=0)
1 (n!=0)
N= 8 の場合、これは、次のように表すことができ、
X_k = Σ_{i=0}^{7} C_(k(2i+1)) x_i
C_n = { 1/2√2 (n==0)
cos(πn/(2N))/2 (n!=0)
1 次元 DCT は 1 つの DCT 係数を求めるのに 8 種の定係数の積和、 8 つの DCT 係数
を求めるためには、式通り計算すると 64 回の積和の処理が必要であることがわかる。
X_{k,l}= 2/N C(k)C(l)Σ_{i=0}^{N-1}Σ_{j=0}^{N-1} x_{i,j}cos(πk(2i+1)/2N)cos(πl(2j+1)/2N)
x_{i,j}= 2/N Σ_{k=0}^{N-1}Σ_{l=0}^{N-1}C(k)C(l)x_{k,l}cos(πk(2i+1)/2N)cos(πl(2j+1)/2N)
2 次元 DCT は 1 次元 DCT の i と k が j と l に変わったものが、さらに乗算されている形である。
2 次元 DCT は 1 次元 DCT の処理に分解でき、しかも計算量も少なくなる。
これはブロック内の各行で x 方向に 1 次元 DCT し、結果を同じ行に戻し、
つぎに y 方向に 1 次元 DCT を各列で行ない、結果を同じ列に戻すことである(図 6)。
これを式で書けば、 2 次元 DCT の式 ( 7 ) はつぎのように分解できる。
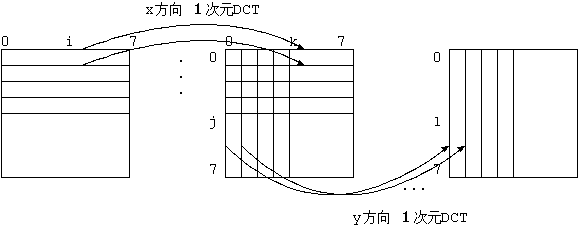
g_{k,j}= √(2/N)C(k)Σ_{i=0}^{N-1}x_{i,j}cos(πk(2i+1)/(2N))
X_{k,l}= √(2/N)C(l)Σ_{j=0}^{N-1}g_{k,j}cos(πl(2j+1)/(2N))
2 次元 DCT の上記の方法では、 8x8 の 2 次元 DCT の計算には 16 回の 1 次元 DCT を
行なうことになり、64*16 の積和、つまり画素あたり 16 回の積和が必要となる。
DCT には高速化アルゴリズムがあり、64 回の積和が 11 回の積と、29 回の和にまで削減
できる。それについては後述する。
入力データの値は差分値でありうるので、-255 〜 255 の範囲の値であり、 変換後の DCT 係数の値の範囲は -2040 〜 2040 となる。 画像符号化に DCT, IDCT を使う場合に、その入出力は整数でありながら実数計算 であることから、後述する IDCT ミスマッチ問題が発生する。DCT, IDCT の計算法 は画像符号化の標準化では規定されず、IDCT の精度だけが規定される。
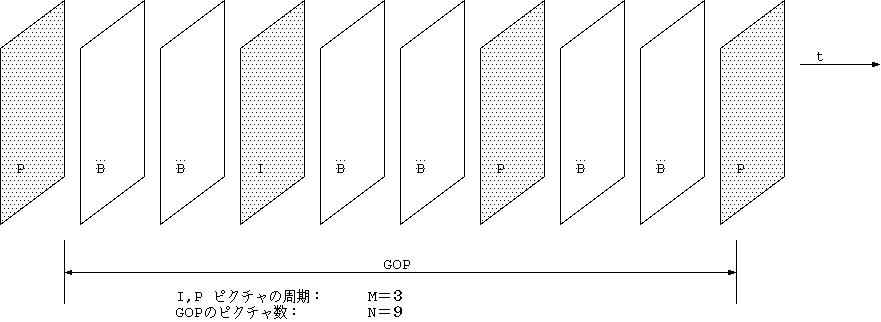
ある単位の動画像、何枚かの画像をまとめて GOP (Group of Pictures)とよび、 その単位での独立再生ができるようにしている。GOP は途中からの再生を可能に するため、シーケンスヘッダを付けうる。 シーケンスヘッダには画像の大きさ、画素縦横比など、デコーダが再生のために 必要な初期データが入っている(図 7)。また、GOP は編集の単位とも考えられ、 編集用の機能が付いている。

I-picture: フレーム内(Intra frame)符号化画面。 この画面では、すべてのマクロブロックが Intra 符号化される。 I-picture の目的は GOP の独立性を容易に保つためにある。
P-picture: フレーム間(Predictive)予測符号化画面。 ITU-T H.261 と同じくマクロブロック毎に Intra 符号化と Inter 符号化が選択できる画面タイプである。
B-picture: 双方向 (Bidirectional)予測符号化画面。 MPEG 特有の画面タイプであり、過去の I または P-picture を予測に使う だけでなく未来の I, P-picture をも予測に使うことができる画面である。
未来の画像を予測に使うということはどういうことかと思われるかも 知れないが、単に処理順を変更するのである。I,P-picture は先に処理し、 間にある B-picture は後で処理するのである。
(4) の内挿的予測とは forward 予測と backward 予測の 2 つの 予測マクロブロックを対応画素間で、丸め付き平均することであり、 2 重写しになったのを予測に使うと考えてよい。このとき、動きベクトルは マクロブロックに 2 個付くので B-picture の動きベクトルは マクロブロックに 0 個から 2 個付く。
この画面は予測誤差を符号化せずに、受動的な内挿画面の役割 を行なうことができるが、基本的には、 P-pictureと同様に予測誤差を 符号化して予測に加算できることも重要な特徴である。 ( 画面の大半の領域では受動的内挿画面とし、部分的に予測誤差を 符号化することが多い。) また、同じ動きベクトルを前後に利用するのではなく、前後に独立な ベクトルを使うことも重要な特徴である。

デコーダは B-picture はデコードし即時に表示するが、 I, P-picture はデコードしても、次のいくつかの B-picture の処理が終わった後に表示する。
このことは、エンコーダとデコーダを通すと I, P-picture の周期 (M) だけの遅延が発生することを意味する。通信に使う場合には、この 遅延の大きさが問題となる。
双方向予測を用いる事による予測精度向上は確認の報告がなされている。 量子化を I,P,B で変えなくても B-picture はかなりの効果がある。
また、 I, P-picture は画質を高く保ち、B-picture の画質は低く抑える という、符号化制御によって平均 SNR が向上することも確認されている。 つまり、 B-picture は使い捨てであり、 I,P-picture は次に予測に利用 する画像であるから、平等に扱う必要はない。I と P の間にはそのような 関係はないのでほぼ平等にする。
以上の理由によって、画像にもよるが約 2 dB の SNR の向上が期待できる。
MPEG-1 のシミュレーションモデルでは B-picture の量子化パラメータは I, P-picture の 2 倍にする条件であった。SNR の変動を嫌って、MPEG-2 の テストモデルではこの比率を 1.4 倍にしている。
Closed GOP フラグは エンコード時にたてられるフラグで、 最初のいくつかの B-picture が以前の GOP に依存しないことを表す。 編集重視のビットストリームは閉じた GOP をつかうことになろう。
Broken Link フラグは Closed GOP でないビットストリームを 編集によって切り取り、つなげたときに立てるフラグである。 デコーダは Broken Link フラグがあるときには GOP の先頭 のいくつかの B-picture を表示しない。
GOP 内の Picture 数 (N)、I, P-picture の周期 (M) に制限はなく、 (1) メディア上の並びで、GOP の最初は I-picture。 (2) 原画面順で GOP の最後は I, P-picture。
という以外に制限はない。標準化はデコーダ仕様だけを 規定するものだからである。常識的には N は 0.4 秒から 数秒の周期であろうし、M は 3 から 6 程度といわれている。 (1)から原画面順では I-picture は一般に先頭ではないことがわかる。 (2)の条件はもし、GOP の最後に B-picture が許されるなら、 その B-picture はどの 2 枚を予測に使うかの Decoder の判断を複雑に するからである。
ITU-T H.261 では 121 型のブロック内に閉じた 2 次元 ループ内フィルタが使われていたが、MPEG では比較的 ビットレートが高いため、強いローパスフィルタは不必要 とされ、ループ内フィルタはもたず、ハーフペル MC が ループ内フィルタの代わりをするようになった。
半画素位置を求めることは、画像に [0.5, 0.5] のインパルス 応答をもつローパスフィルタを通して画像をゆるくぼやかす 働きをもっている。 これによる効果が画像によってはかなり大きいようである。 動きベクトルをオリジナル同士から求める場合でも、 水平方向の半画素位置の選択は 50 % を大きく上回っている。
B-picture ではハーフペル MC の双方向予測を行なう。 前後両方の予測を使う内挿的マクロブロックの場合には、 前後 2 つのハーフペル MC 値の丸め付き平均を予測値とする。

エフコードの表すフレーム間隔は現実のフレーム間隔と違ってもよい。 例えば、 M= 3 の P-picture では現実のフレーム間隔は 3 であるが、 3 は用意されていないので 4 を使うことができる。
また Picture レイヤにはベクトルが整数であることを表す、 full_pel_forward_vector ( B-picture ではそれと full_pel_backward_vector ) が用意されていて、これが 1 のときは動きベクトルは整数単位とする。
動きベクトルは +- 16 までを表す VLC と f_code - 1 ビットの 残りのビットでひとつの成分の差分が表現され、その記述範囲は 半画素単位(または 整数画素単位)でフレーム間隔が 1 の時、 +15 から -16、 2 のときは +31 から -32、4 のときは +63 から -64 まで、 8 のときは +127 から -128 までである。詳しくは後述する。
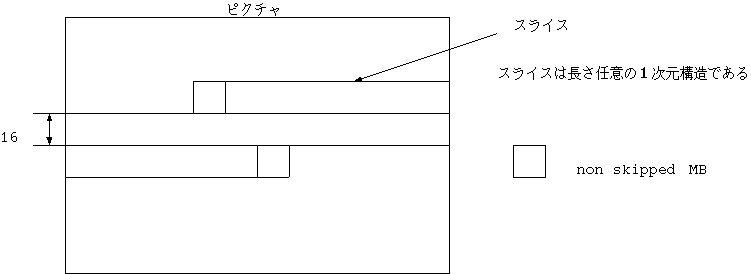
MPEG では ピクチャフォーマットを自由にするため、 GOB に相当するレイヤ として スライス(Slice) が定義された。これはオーバラップせず、 ギャップを持たない、長さ任意個(1 以上)のマクロブロックの 1 次元構造で、 画面の右端に達すると、 1 行下の左端に連続するような帯である (図 11)。
スライスの最初と最後のマクロブロックは nonskipped であると規定している。 スライスは量子化の値 ( 5 bit の SQUANT [1-31]) だけでなく、そのスタートコード の中に先頭のマクロブロックの画面内の垂直位置をもつ。水平位置には後述する MBA が使われ、以前のマクロブロックの位置を上の帯の右端としている。
以上の仕組みからスライスは独立に画像再現できる単位である。伝送系のエラーによって、 あるスライスが崩れた場合も、次のスライスからは回復できるのである。
符号化の仕組み、方法 (予測 (MC) や符号化のモード)は は 16x16 のマクロブロックを単位として示され、マクロブロックタイプで表される。 それに対して DCT は 8x8 のブロックを単位としている。そのため、 マクロブロックは 6 個のブロックをまとめて扱うことになる。
MBA で飛ばされる( "skipped" )マクロブロックタイプは、P-picture では Non MC ( 単純フレーム間予測 )で、Not Coded (DCT 係数のコードをもたないマクロブロック)タイプ、B-picture では、 ひとつ前のマクロブロックと予測方向(順、逆、内挿)が同じで、動ベクトルが同じで、 Not Coded のマクロブロックである。I-picture ではスキップトマクロブロックはない。
表 1 マクロブロックアドレス
macroblock_address_ 増分の値 macroblock_address_ 増分の値
increment のVLC increment のVLC
1 | 1 0000 0101 00 | 19
011 | 2 0000 0100 11 | 20
010 | 3 0000 0100 10 | 21
0011 | 4 0000 0100 011 | 22
0010 | 5 0000 0100 010 | 23
0001 1 | 6 0000 0100 001 | 24
0001 0 | 7 0000 0100 000 | 25
0000 111 | 8 0000 0011 111 | 26
0000 110 | 9 0000 0011 110 | 27
0000 1011 | 10 0000 0011 101 | 28
0000 1010 | 11 0000 0011 100 | 29
0000 1001 | 12 0000 0011 011 | 30
0000 1000 | 13 0000 0011 010 | 31
0000 0111 | 14 0000 0011 001 | 32
0000 0110 | 15 0000 0011 000 | 33
0000 0101 11 | 16 0000 0001 111 | macroblock_stuffing
0000 0101 10 | 17 0000 0001 000 | macroblock_escape
0000 0101 01 | 18
I-picture では intra と intra +Q ( +Q はMQUANT 付きの意味 )の 2 種類である。
P-picture では MC Coded, NonMC Coded, MC NotCoded, Intra, MC Coded +Q, NonMC Coded +Q, Intra +Q の 7 種である。MC はすべて順方向予測である。
B-picture では Intra 2 種と、 3 種の予測方向(順、逆、内挿)にそれぞれ、 NotCoded, Coded, Coded +Q があるため、2 + 3 * 3 = 11 種となる。 NonMC のタイプはない。単純フレーム予測には動きベクトル (0,0) を伝送する。
マクロブロックのタイプからあとのシンタクスは 3 つの画像タイプに共通で、 +Q (macroblock quant が 1) のタイプでは 5 bit の MQUANT ([1,31])が続き、 順方向 MC または 逆方向 MC があるときの(macroblock motion forward または macroblock motion backward が 1 ) MC タイプでは動きベクトルの差分 VLC が 2 個または 4 個続く。動きベクトルは x 成分の VLC と y 成分の VLC を並べる。 NonMC では動きベクトルを省略し、単純フレーム間予測を行なう。
NotCoded は DCT 係数を持たないことを表す。( IDCT の処理は不要である。) Coded ( macroblock pattern が 1 )でも 6 個のブロックにすべて DCT 係数が あるわけではないので、 後述するマクロブロックパターン(CBP)が用意される。 Intra では 6 個のブロックとも DCT 係数があるとして、 CBP はつけない。 MQUANT はスライスの最後まで、後続するマクロブロックに影響する。
表 2 マクロブロックタイプの VLC
macroblock_ macroblock_ macroblock_ macroblock_ macroblock_ macroblock_
type quant motion_ motion_ pattern intra
VLC forward backward
(a) I-picture
1 0 0 0 0 1
01 1 0 0 0 1
(b) P-picture
1 0 1 0 1 0
01 0 0 0 1 0
001 0 1 0 0 0
00011 0 0 0 0 1
00010 1 1 0 1 0
00001 1 0 0 1 0
000001 1 0 0 0 1
(c) B-picture
10 0 1 1 0 0
11 0 1 1 1 0
010 0 0 1 0 0
011 0 0 1 1 0
0010 0 1 0 0 0
0011 0 1 0 1 0
00011 0 0 0 0 1
00010 1 1 1 1 0
000011 1 1 0 1 0
000010 1 0 1 1 0
000001 1 0 0 0 1
(d) D-picture
1 0 0 0 0 1
P-picture ではスライスの先頭と、一つ前が MC でない場合(intra か NonMCの場合)、差分は使わずそのままの値を用いる。 スライスが 1 行を越える場合も画面の右端から 1 行下の左端に動きベクトルの 予測は連続する。
B-picture では、2 つの動きベクトルがありえる。動きベクトルの差分の リセットは スライス先頭と Intra だけとする。すなわち、左隣にその方向の 予測が使われない場合も動きベクトルの予測値を連続させる。 例えば、マクロブロックが forward MC, backward MC, interpolative MC と並ぶとき、 2 番目のマクロブロックでは forward の予測は使われないのに 3 番目の マクロブロックでは forward, backward とも差分値である。forward の動きベクトル は 1 番目の動きベクトルに加算して再現される。
さて差分動きベクトルの符号化表現であるが、表 3 の VLC の表す値が 0 以外のときに このあとに、残りのビットを付け、動きベクトルの差分表現を拡大している。
表 3 差分動きベクトルの VLC motion_VLC_code code 0000 0011 001 -16 0000 0011 011 -15 0000 0011 101 -14 0000 0011 111 -13 0000 0100 001 -12 0000 0100 011 -11 0000 0100 11 -10 0000 0101 01 -9 0000 0101 11 -8 0000 0111 -7 0000 1001 -6 0000 1011 -5 0000 111 -4 0001 1 -3 0011 -2 011 -1 1 0 010 1 0010 2 0001 0 3 0000 110 4 0000 1010 5 0000 1000 6 0000 0110 7 0000 0101 10 8 0000 0101 00 9 0000 0100 10 10 0000 0100 010 11 0000 0100 000 12 0000 0011 110 13 0000 0011 100 14 0000 0011 010 15 0000 0011 000 16
動きベクトルの 1 成分のデコードはたとえば、次のような C 言語プログラムで 書くことができる。 ( get_flc( n ) は、 bitstream から n bit だけとる関数、 get_mv_vlc() は、表 3 の VLC の 符号ビット以外を bitstream から読み取る 関数とする。)
decode_mvc(mvc,f_code)
{
int v, frame_dist, sgn, max, min, r;
v= get_mv_vlc(); /* 動きベクトル VLC の符号以外をとる */
if(v==0) return mvc; /* 値が 0 なら、まえの値のまま終了 */
sgn=get_flc(1); /* 値が 0 以外のとき、符号をとる */
frame_dist= 1<<(f_code-1);
r = 0;
if(frame_dist>1)r= get_flc(f_code-1);/* 残りビットをとる */
max= 16*frame_dist - 1; /* 最大値 */
min= -16*frame_dist; /* 最小値 */
mvc+= sgn*( (v - 1)*frame_dist + (r + 1)); /* 差分を加算 */
if( mvc < min ) mvc+= 32*frame_dist; /* 最小値より小 */
else if( max < mvc ) mvc-= 32*frame_dist; /* 最大値より大 */
return mvc; /* 動ベクトルの成分を返す */
}
差分値は VLC の値 "v" とそれに続く(f_code -1) ビットの表す値 "r" で
次式ように再現させる。
sgn * ((v - 1)* frame_dist + (r + 1))
動き 0 には残りビットが付かないため、例えばフレーム間隔が 4 のとき、v = 1 なら r = 0,1,2,3 それぞれが差分 1,2,3,4 を、 v = 2 なら 差分 5,6,7,8 を表すために行なわれる式である。
差分の表現範囲と絶対値の表現範囲を同じにしているため、 差分の加算の後の、動ベクトルの絶対値の再現には差分値に 2 つの解釈を 許し、ベクトルの成分値が、 -16 x フレーム間隔 (最小値)と、 16 x フレーム間隔 - 1 (最大値) の間にこない場合は他の側の解釈をとり、 32 x フレーム間隔を加算または減算して再現する。
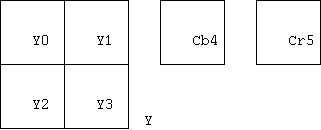
cbp= 32* P_1 + 16* P_2 + 8* P_3 + 4* P_4 + 2* P_5 + P_6
P_i の i は "ブロックとマクロブロック" の項で図示したブロックの番号(図 5)。 その中に係数があるとき、P_i = 1 そうでないとき 0 である。
CBP を用いることによって後述するブロックレイヤ (DCT 係数の VLC の EOB (End Of Block)までの並び)は、1 個から 6 個まで変化する。
表4マクロブロックパターン(coded block pattern)の VLC VLC cbp VLC cbp 111 60 0001 1100 35 1101 4 0001 1011 13 1100 8 0001 1010 49 1011 16 0001 1001 21 1010 32 0001 1000 41 1001 1 12 0001 0111 14 1001 0 48 0001 0110 50 1000 1 20 0001 0101 22 1000 0 40 0001 0100 42 0111 1 28 0001 0011 15 0111 0 44 0001 0010 51 0110 1 52 0001 0001 23 0110 0 56 0001 0000 43 0101 1 1 0000 1111 25 0101 0 61 0000 1110 37 0100 1 2 0000 1101 26 0100 0 62 0000 1100 38 0011 11 24 0000 1011 29 0011 10 36 0000 1010 45 0011 01 3 0000 1001 53 0011 00 63 0000 1000 57 0010 111 5 0000 0111 30 0010 110 9 0000 0110 46 0010 101 17 0000 0101 54 0010 100 33 0000 0100 58 0010 011 6 0000 0011 1 31 0010 010 10 0000 0011 0 47 0010 001 18 0000 0010 1 55 0010 000 34 0000 0010 0 59 0001 1111 7 0000 0001 1 27 0001 1110 11 0000 0001 0 39 0001 1101 19
例えば、12,10,9,1,0 という数値の並びをすべて丸め付きで 10 で割って 1,1,1,0,0 と表し、10,10,10,0,0 と再現しても誤差は少ない。 この 10 にあたるものが MPEG では quant 値と、次の節で解説する量子化マトリックス の両方に関係する。
逆量子化は、intra の DC 係数以外では、輝度、色差とも次式で行なわれる。 量子化 DCT 係数値を level[i] とし、スライスまたは、マクロブロックレイヤに 記述された 5 bit の quant値 [1-31] を quant とし、
2 つの量子化マトリックスを intra_quant[m][n]、non_intra_quant[m][n]とし、 逆量子化された再現値を rec[m][n]とするとき、次のような処理となる。
i= scan[m][n]; /* zigzag scan */ Intra では、rec[m][n]= 2*level[i]*quant*intra_quant[m][n]/16; Non-intra では、 rec[m][n]= (2*level[i]+sign(level[i]))*quant*non_intra_quant[m][n]/16; if((rec[m][n]&1) == 0)rec[m][n]= rec[m][n]-sign(rec[m][n]); if(rec[m][n] > 2047 )rec[m][n]= 2047; if(rec[m][n] < -2048 )rec[m][n]= -2048;Intra では 2*level*quant*intra_intra_quant[m][n]/16 を行なう。 逆量子化で level に比例した再現を行なうことは、量子化時に丸めが必要であることを意味する。 それに対して、Non-intra では rec[m][n]= (2*level[i]+sign(level[i]))*quant*non_intra_quant[m][n]/16 であり、level の 0.5 倍だけ 0 から離れたものに比例した再現を行う。 逆量子化でこうする事は、量子化で単なる(丸め無しの)割り算が使えることを意味し、 また 0 の近辺を離すことは Non-intra でのノイジーな変化を抑える働きがある。
その後、rec が偶数ならその符号を引く。こうして偶数をさけて奇数のみを再現し IDCT にあたえるのは後述する IDCT ミスマッチを避けるためである。
これに合致する量子化は、係数*16を quant値の 2 倍と量子化マトリックスの積での (Intra では丸め付き、Non Intra では丸めなしに)割算と考えてよい(下式)が、 エンコーダ側の技術であるため、工夫の余地を残している。 intra の DC 係数だけは、逆量子化は 8 倍と定めているので、固定の 8 で丸めつき割り算をする。
qc_{i,j}= { 8 * c_{i,j} // ( QMi_{i,j} * qp ) ( for intra )
8 * c_{i,j} / ( QMn_{i,j} * qp ) ( for non intra )
Intra 用と、Non-Intra用の 2 種類あり、( 上式では、intra_quant[m][n], non_intra_quant[m][n] ) Intra 用と Non Intra 用のデフォールト値は表 5 に示す。 Intra 用の (0,0) 成分は無視される。Non Intra のデフォールトはすべて 16 である。 シーケンスヘッダで両方とも設定できる。
表 5 デフォールトの量子化マトリックス
(a)default intra quantize matrix (b)default non intra quantize matrix
8 16 19 22 26 27 29 34 16 16 16 16 16 16 16 16
16 16 22 24 27 29 34 37 16 16 16 16 16 16 16 16
19 22 26 27 29 34 34 38 16 16 16 16 16 16 16 16
22 22 26 27 29 34 37 40 16 16 16 16 16 16 16 16
22 26 27 29 32 35 40 48 16 16 16 16 16 16 16 16
26 27 29 32 35 40 48 58 16 16 16 16 16 16 16 16
26 27 29 34 38 46 56 69 16 16 16 16 16 16 16 16
27 29 35 38 46 56 69 83 16 16 16 16 16 16 16 16
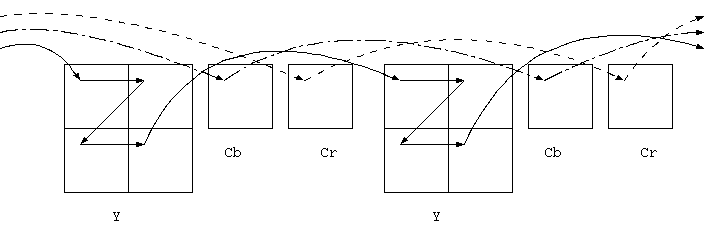
表 6 差分 DC 係数 (a)輝度と色差のサイズの VLC VLC dct_dc_size_luminance VLC dct_dc_size_chrominance 100 0 00 0 00 1 01 1 01 2 10 2 101 3 110 3 110 4 1110 4 1110 5 11110 5 11110 6 111110 6 111110 7 1111110 7 1111110 8 11111110 8
(b)差分 DC 付加コード
DifferentialDC Size Additional code
-255 〜 -128 8 00000000 〜 01111111
-127 〜 -64 7 0000000 〜 0111111
-63 〜 -32 6 000000 〜 011111
-31 〜 -16 5 00000 〜 01111
-15 〜 -8 4 0000 〜 0111
-7 〜 -4 3 000 〜 011
-3 〜 -2 2 00 〜 01
-1 1 0
0 0
1 1 1
2 〜 3 2 10 〜 11
4 〜 7 3 100 〜 111
8 〜 15 4 1000 〜 1111
16 〜 31 5 10000 〜 11111
32 〜 63 6 100000 〜 111111
64 〜 127 7 1000000 〜 1111111
128 〜 255 8 10000000 〜 11111111
表 7 ジグザグスキャン順 (scan[m][n])
1 2 6 7 15 16 28 29
3 5 8 14 17 27 30 43
4 9 13 18 26 31 42 44
10 12 19 25 32 41 45 54
11 20 24 33 40 46 53 55
21 23 34 39 47 52 56 61
22 35 38 48 51 57 60 62
36 37 49 50 58 59 63 64
これを run-level の 2 次元 VLC という。要するにこれは run と level との対 をイベントと考え、 VLC を割当てるものである。
非ゼロ係数の最後を表す符号が EOB (2 bit)である。係数が 64 個ある場合も EOB はつける。run と level の対について、113 個の VLC が用意されている(表 8)。 これらには eob と escape も含められている。
VLC が用意されていない run-level 対は、VLC 中の escape に続く、 run と level の 固定長符号(FLC)で表現する(表 9)。
level の絶対値が 127 までのときは、20 bit の形式 ( escape (6 bits) + run (6 bits) + level (8 bits) )であり、 128 から 255 までは 28 bit の形式 ( escape (6 bits) + run (6 bits) + level (16 bits) )である。
level は、-255 <= level <= 255 に制限されているので、 それを越える level 値は表現できない。小さな量子化値を使ったときに たまにそれが発生し、大きな誤差が発生する現象がある。
表 8 DCT 係数の VLC ("s" はlevelの符号であり"0"は正,"1"は負を示す。)
DCT 係数の VLC run level
10 end_of_block
1 s (最初の係数用) 0 1
11 s (以降の係数用) 0 1
011 s 1 1
0100 s 0 2
0101 s 2 1
0010 1 s 0 3
0011 1 s 3 1
0011 0 s 4 1
0001 10 s 1 2
0001 11 s 5 1
0001 01 s 6 1
0001 00 s 7 1
0000 110 s 0 4
0000 100 s 2 2
0000 111 s 8 1
0000 101 s 9 1
0000 01 escape
0010 0110 s 0 5
0010 0001 s 0 6
0010 0101 s 1 3
0010 0100 s 3 2
0010 0111 s 10 1
0010 0011 s 11 1
0010 0010 s 12 1
0010 0000 s 13 1
0000 0010 10 s 0 7
0000 0011 00 s 1 4
0000 0010 11 s 2 3
0000 0011 11 s 4 2
0000 0010 01 s 5 2
0000 0011 10 s 14 1
0000 0011 01 s 15 1
DCT 係数の VLC run level 0000 0010 00 s 16 1 0000 0001 1101 s 0 8 0000 0001 1000 s 0 9 0000 0001 0011 s 0 10 0000 0001 0000 s 0 11 0000 0001 1011 s 1 5 0000 0001 0100 s 2 4 0000 0001 1100 s 3 3 0000 0001 0010 s 4 3 0000 0001 1110 s 6 2 0000 0001 0101 s 7 2 0000 0001 0001 s 8 2 0000 0001 1111 s 17 1 0000 0001 1010 s 18 1 0000 0001 1001 s 19 1 0000 0001 0111 s 20 1 0000 0001 0110 s 21 1 0000 0000 1101 0 s 0 12 0000 0000 1100 1 s 0 13 0000 0000 1100 0 s 0 14 0000 0000 1011 1 s 0 15 0000 0000 1011 0 s 1 6 0000 0000 1010 1 s 1 7 0000 0000 1010 0 s 2 5 0000 0000 1001 1 s 3 4 0000 0000 1001 0 s 5 3 0000 0000 1000 1 s 9 2 0000 0000 1000 0 s 10 2 0000 0000 1111 1 s 22 1 0000 0000 1111 0 s 23 1 0000 0000 1110 1 s 24 1 0000 0000 1110 0 s 25 1 0000 0000 1101 1 s 26 1
表 8 DCT 係数の VLC (続き) DCT 係数の VLC run level 0000 0000 0111 11 s 0 16 0000 0000 0111 10 s 0 17 0000 0000 0111 01 s 0 18 0000 0000 0111 00 s 0 19 0000 0000 0110 11 s 0 20 0000 0000 0110 10 s 0 21 0000 0000 0110 01 s 0 22 0000 0000 0110 00 s 0 23 0000 0000 0101 11 s 0 24 0000 0000 0101 10 s 0 25 0000 0000 0101 01 s 0 26 0000 0000 0101 00 s 0 27 0000 0000 0100 11 s 0 28 0000 0000 0100 10 s 0 29 0000 0000 0100 01 s 0 30 0000 0000 0100 00 s 0 31 0000 0000 0011 000 s 0 32 0000 0000 0010 111 s 0 33 0000 0000 0010 110 s 0 34 0000 0000 0010 101 s 0 35 0000 0000 0010 100 s 0 36 0000 0000 0010 011 s 0 37 0000 0000 0010 010 s 0 38 0000 0000 0010 001 s 0 39
DCT 係数の VLC run level 0000 0000 0010 000 s 0 40 0000 0000 0011 111 s 1 8 0000 0000 0011 110 s 1 9 0000 0000 0011 101 s 1 10 0000 0000 0011 100 s 1 11 0000 0000 0011 011 s 1 12 0000 0000 0011 010 s 1 13 0000 0000 0011 001 s 1 14 0000 0000 0001 0011 s 1 15 0000 0000 0001 0010 s 1 16 0000 0000 0001 0001 s 1 17 0000 0000 0001 0000 s 1 18 0000 0000 0001 0100 s 6 3 0000 0000 0001 1010 s 11 2 0000 0000 0001 1001 s 12 2 0000 0000 0001 1000 s 13 2 0000 0000 0001 0111 s 14 2 0000 0000 0001 0110 s 15 2 0000 0000 0001 0101 s 16 2 0000 0000 0001 1111 s 27 1 0000 0000 0001 1110 s 28 1 0000 0000 0001 1101 s 29 1 0000 0000 0001 1100 s 30 1 0000 0000 0001 1011 s 31 1
表 9 escape 符号に続いて符号化される run 及び level FLC run 0000 00 0 0000 01 1 0000 10 2 ... ... 1111 11 63
FLC level 1000 0000 0000 0000 (禁止) 1000 0000 0000 0001 -255 1000 0000 0000 0010 -254 ... 1000 0000 0111 1111 -129 1000 0000 1000 0000 -128 1000 0001 -127 1000 0010 -126 ... ... 1111 1110 -2 1111 1111 -1 0000 0000 (禁止) 0000 0001 1 ... ... 0111 1111 127 0000 0000 1000 0000 128 0000 0000 1000 0001 129 ... 0000 0000 1111 1111 255
x_{0,0} = 1/4 Σ_{i=0}^{7}Σ_{j=0}^{7} C(k) C(l) X_{k,l} cos(πk/16) cos(πl/16)
となり、
x_{0,0} = (X_{0,0} + X_{4,0} + X_{0,4} + X_{4,4})/8 + ....
であるが、その他の係数が 0 とすると、括弧内が 4 の倍数で、 8 の倍数でない とき、結果は(整数+ 0.5)となり、標準化が規定する IDCT の精度をどんなに高めても 丸めによって結果は 1 だけくいちがう可能性がある。
丸めの方法を規定する事によってこれを避けることはできるが、標準化の前にすでに DCT, IDCT のチップは市販されていた。それゆえ、IDCT に与える数値 X_{k,l} をすべて 奇数に制限したのである。これによって IDCT ミスマッチ問題の大半が解決されたと いわれる。しかしながら、高画質、高 bitrate においては奇数への制限は行なうこと ができないことが明らかであり、MPEG-2 では新たな IDCT ミスマッチ対策が採られた。
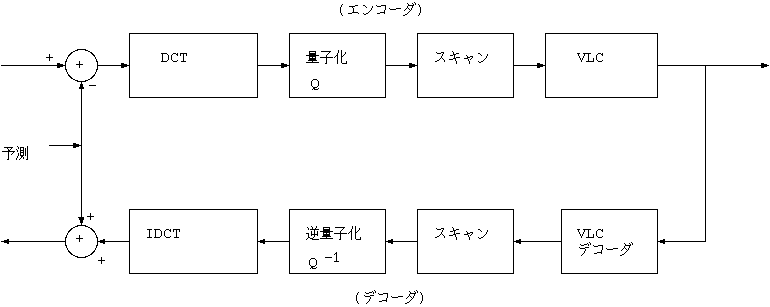
メディアからのデータの流れは MPEG System 部分で分離され、 Video のビットストリームは、VLCデコーダで各種のデータに分離される。 画像タイプ、マクロブロックタイプなどはデコーダの制御に使われる。 動きベクトルは フレームメモリからの MC に使われ、 通常全体の 90 % 以上を占める最下層の量子化DCT係数(2 次元 VLC)は、 逆量子化、逆 DCT 変換され、差分画像データとなる。
I, P-picture であれば、 一方のフレームメモリの画面の、マクロブロック毎に動き補償された、 対応する位置の画素値に加算されて、他方のフレームメモリに蓄える。 I, P-picture のデコード処理中には、 現在書き込中でない方のフレームメモリを表示出力する。
B-picture では 2 つのフレームメモリから並列に MC が行なわれる。 それぞれに用意された動きベクトルを使って、 動き補償した予測画素値に加算して B-picture の再生画像を作り、 これはどこにも蓄えずに、現在デコード処理中の画像をそのまま表示出力する。
B-picture では、現在デコード処理中の画像をそのまま表示出力し、 I, P-picture では現在 MC に使用している参照画像を表示することで、 図 9 に示したデコード後の画面の順番がえ(I, P-picture の遅延)が行なわれる。
2 つのフレームメモリは、一方に書くとき、他方を読みだすので、 ダブルバッファの必要はないが、読み出しは P-picture 時に動き補償用と、 表示出力用の 2 回のアクセスが必要となる。
ITU-T H.261 デコーダと異なる点は、フレームメモリの数が多い。 (1枚から2枚になった) ループ内フィルタを持たない。 動作は画面タイプによって異なり、出力の画面順替えがあることなどである。
実際のインプリメントにおいて、このデザインのように 2 つの画像メモリを持つ必要はない。 1 つの汎用のメモリで 2 つのフレームメモリと入力バッファまで併用することが、 最近の MPEG デコーダの傾向である。その際にメモリの速度を上げずに済ますには、 メモリのデータ幅を大きくする。
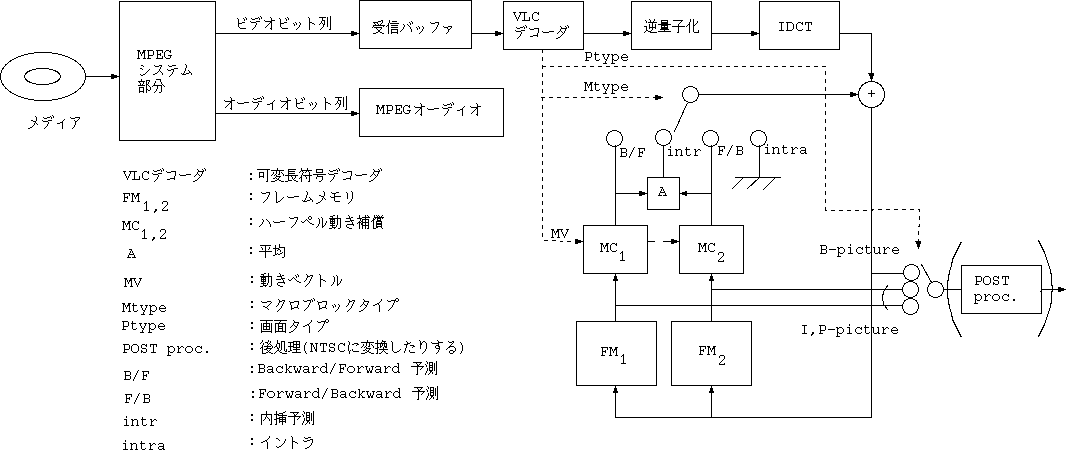 図 14 MPEG デコーダのブロック図
図 14 MPEG デコーダのブロック図
エンコーダを作るためには、これらの標準化の外の技術を熟知する必要がある。 ここではエンコーダの動きベクトル検出そして、符号化制御、プリポスト処理の技術を解説する。
動きベクトル検出には、(1)性能を落とさずに計算量を減らそうという方向と、 (2)性能を上げようという方向とがあるが、 もとの単純な計算方法が膨大な計算量を要求しているため、 どうしても短期的な研究の方向は(1)に片寄ってくる。
探索範囲は動きベクトルの空間での制限であり、 シンタクス上の動きベクトルの表現範囲以内に設定される。 ピクチャレイヤで f_code を定めたときにすでに動きベクトルの表現範囲は 決まってしまう。その範囲以外は表現出来ないのである。
参照画面上の画素位置はブロックの位置と動きベクトルの和である。 画面を少しでもはみ出すような動きベクトルは許されないから、 例えば画面の左端のマクロブロックでは x 方向にマイナスの値は使えない。
計算量は"差の絶対値"を求める計算を単位として、マッチング窓の面積と探索範囲の面積 の積となる。基本的な探索法であり、計算量は大きいが単純な処理のため LSI 化 には有利な方法である。"差の絶対値" の代わりに"差の 2 乗"を使ってもよいが、 計算量が膨大なので、ほとんどが "差の絶対値" を使う。 動きベクトルの空間で探索が密に連続していることを利用したメモリアクセスの回数の削減も可能で、 マッチング窓に探索範囲を周辺に広げた範囲のメモリアクセスで済むため、 多くの MVD の LSI はこの方式を使っている。
まず、中心の (0,0) と周囲の x, y 方向に +-4 の 8 点のマッチングを調べ、 9 点の中の最小誤差点を求め、つぎにその点の周りの 8 点を+-2 で調べ、 9 点の中の最小誤差点を求め、最後にその点の周りの 8 点を+-1 で調べ、 9 点の中の最小誤差点を求める。
計算量では、 1 + 3 x 8 = 25 回の 16 x 16 のマッチングとなり、 +-7 のフルサーチ(15 x 15= 225 回の 16 x 16 のマッチング)と比べると、 9 分の 1 となる。
ITU-T H.261 リファレンスモデル RM8 では、輝度画像からマクロブロック単位に、 誤差評価は絶対値和、探索範囲を +- 7 画素とした 3 step 法を用いて検出すると定めていた。
計算量では上位階層の処理を隣り合うマクロブロックで共用するため、 3 step 法よりさらに少なくなり、(+-7, +-7)の範囲のサーチには 9 +( 9 /4 ) + ( 9 /16 )= 約 12 回のブロックマッチングですむ。
再生画像を使わないため、真の動きに近いものを求めることができるが、 実際に参照画像となる再生画像からベクトルを求めないため、MC の予測誤差を 減少させる効果は再生画像からのベクトル検出よりつねに悪いと予想され、 高画質符号化においては両者は差がなくなっていくと思われる。
利点としてはシミュレーションの動きベクトル検出の処理と、 符号化の処理を分離させることができるため、 MPEG のシミュレーションモデル SM 1 〜 3 で採用された。
なお、オリジナル同士の動きベクトル検出はエンコーダに I, P-picture の 周期 M 枚の入力画像バッファが必要となる。
MPEG では離れたフレームの間の動きベクトルが必要であるため、 フレーム間隔 f のベクトルサーチは、その初期ベクトルを同じ参照画像のフレーム 間隔 f -1 の画像の求められたベクトルとして、x, y 両方向に +-7 の フルサーチを行なう。フレーム間隔 0 のベクトルは (0,0) とする。
つまり、参照画像が 0 番目で、入力画像が 3 番目の画像のマクロブロックの動き ベクトルの探索初期点は、参照 0 番目から入力 2 番目の画像への対応する マクロブロックの動きベクトルとし、 またその探索の初期点は、0 番目から 1 番目の画像への対応するマクロブロック の動きベクトルとするのである。
エンコード処理順との対応が良くないので オリジナル同士の動きベクトル検出 にしか使えない。例えば、0 番目と 3 番目の画像が I, P-ピクチャで間の 1, 2 が B-ピクチャであるときは 3 番目の画像の動きベクトルが先に必要 であるのに、その計算に 1, 2 の画像の動きベクトルを必要とするのである。
発生符号量が多すぎるときには量子化を粗くすることで発生符号量を減らそう というもので、いわゆる積分制御である。量子化ステップサイズから 発生符号量までは逆数の関係があり、非線形系でもある。
まず、I,P,B-picture の初期符号量を設定する。 NTSC 圏 M = 3 では I=200 kbit, P=64kbit, B=12 kbit とした。( M = 2 ではそれぞれ 127,56,8 ) M = 3, N = 15 では I + 4P + 10B が GOP の符号量 576 kbit ( 1152 kbit/sec )となる。
各 Picture の符号化前に、最新の各 Picture の発生符号量( I, P, B ) を使って、 Slice 毎にバッファから出ていく符号量 Ni, Np, Nb を次式によって計算し、
Ni = I * 1150 / bit_rate / number_of_slice
Np = P * 1150 / bit_rate / number_of_slice
Nb = B * 1150 / bit_rate / number_of_slice
bit_rate = (I + 4P + 10B) * ( 30 / N )
各スライス毎に、 Ni, Np, Nb のいずれかをバッファからとりさり、発生符号量を加える。 エンコーダの出力バッファ長は 120 kbit とし、
step_size = 2 + buffer_fullness (kbit) / 2
Slice ごとにその fullness を使って stepsize ( 2 から 62 ) を決めるが、 B-picture では その感度を 2 倍にする。これによって、 B-picture では stepsize は 他の picture の stepsize の約 2 倍になる。B-picture では粗く量子化した画像を使い、 I,P-picture では細かく量子化した画像をもつことで画質が向上し、全体の SN 比も向上する。 SM3 にはレートコントロールについては正確には書かれていない。
SM3 は公開書類であるのに、SM2 からの修正と CD 作成とが同時という 忙しい時期に作られ、その後の保守がなされていないため、Slice 単位になって いないとか、 B-picture の感度について不明確なままに固定されてしまっている。 さらに B-picture でのフレーム間隔による比率内挿、"8-Escape" という 8x8 ブロックへの MV の拡張などが残っている。これらはすべて最後の段階で MPEG のアルゴリズムとしては消去したものである。
SM3 のレートコントロールは I, P, B-picture の発生符号量の違いには考慮した ものになっているが、MQUANT 制御が使われていないとか、GOP 毎の符号量制御は 十分でない。これについては、後述の MPEG-2 の TM0 レートコントロール を参考にしていただきたい。
BD = 1/256 Σ_{i=0}^{15}Σ_{j=0}^{15}|S_{i,j}-S'_{i,j}|
DBD = 1/256 Σ_{i=0}^{15}Σ_{j=0}^{15}|S_{i,j}-S'_{i+mvx,j+mvy}|
ここに (mvx,mvy) : 動ベクトル
S : 入力画像
S' : 1 フレーム前の再生画像
とし、Block Difference (BD)と Dispalced Block Difference (DBD)
の大きさによって判定する。
BD <= 1.0 なら、NonMC とする。そうでないとき、{
( DBD >= ( BD - 3.0 )/1.1 + 2.7 ) または、
( BD <= 3.0 かつ、DBD >= BD / 2.0 ) なら NonMC とし、
そうでないとき、 MC とする。 }
ただ、Non MC タイプの利用による効率向上は MPEG のビットレートでは 大したことがなく、MPEG-2 のテストモデルでは Non MC タイプはむしろ 多用しない方向になっている。つまり、動きベクトルが (0,0) が動きベクトル を使ったときより自乗エラーが小さいときに NonMC を使うようにしている。 これは Non MC タイプの多用が画面に固定されたノイズを残すという欠点 のためである。
intra_inter(o,s)
int o[16][16]; /* input luminance MB */
int s[16][16]; /* mc pred. luminance MB */
{
int i,j;
int var,varor,mwor;
var= varor= mwor= 0;
for(i=0;i<16;i++){
for(j=0;j<16;j++){
int or,dif;
or= o[i][j];
dif= or - s[i][j];
var= var + dif*dif;
varor= varor+ or*or;
mwor= mwor+ or;
}
}
var= var/256;
varor= varor/256 - mwor/256 * mwor/256;
if( varor < var && var > 64 )intra= 1; else intra= 0;
return intra;
}
601 から SIF への前処理には、フィールドドロップ (even field を drop する。 (odd field とは最上の完全ラインを含むフィールド。 ) )によって縦方向に 1/2 にサブ サンプルし、輝度は横方向 (色差は縦横) に 7 タップフィルタ ([-29, 0, 88, 138, 88, 0, -29] //256]) を用いて、さらに 1/2 にサブサンプルする。 このフィルタは高域の持ち上がりが多少あり画像の性質が良かったため選択された。
後処理の SIF から CCIR 601 への拡大に使う内挿フィルタ (interpolation filter) は 7 タップの FIR フィルタ ( [-12, 0, 140, 256, 140, 0, -12] //256 ) で、 輝度は縦横に、色差は縦横縦と拡大する。SIF の周辺は黒色画素があるとする。 このフィルタは画素の上ではその値自体を使い、 画素間では [-12,140,140,-12]//256 で内挿することを表している。 // は 丸め付き割り算である。
それ以外のプリポスト処理としてはカメラからのランダムノイズ除去や、 通常照明によるフリッカー除去などが行なわれることがある。 H.261 のような超低ビットレートではポスト処理としてブロック歪み除去と、 モスキートノイズ除去が重視される。これらには目的に適合した非線形フィルタが有効である。
picture start code 00000100 slice start code 00000101 - 000001AF reserved 000001B0 - 000001B1 user data start code 000001B2 sequence header code 000001B3 sequence error code 000001B4 extension start code 000001B5 reserved 000001B6 sequence end code 000001B7 group start code 000001B8 system start code 000001B9 - 000001FF
シーケンススタートコードのあとに内容は、 画像の水平サイズ(12bit)、垂直サイズ(12bit)、 画素アスペクト比(4bit)、ピクチャレート(4bit)、 ビットレート(18bit)、VBV バッファサイズ(10bit)、 制約パラメータフラグ(1bit)、2つの量子化マトリックス のロードフラグ(1 bit)と内容(64 個の 0 以外の 8 bitで Zigzag 順。) などからなる。
制約パラメータフラグ(1bit)の内容は、
・画像の水平サイズ <= 768 pels, ・垂直サイズ <= 576 pels, ・画像内のマクロブロック数 <= 396 , ・毎秒のマクロブロック数 <= 396 * 25, ・画像レート <= 30, ・forward_f_code <= 4, ・backward_f_code <= 4 ・VBV バッファサイズ <= 327680 bits (20 * 1024 * 16 つまり 40 k bytes), ・ビットレート <= 1,856,000 bit/secである。
途中からの再生のためにシーケンスヘッダが付いた GOP では途中からの再生のときは最初の M-1 枚の B-picture をすてる必要がある。(IS 段階で必須でないことに変った。)
GOP レイヤには Closed GOP フラグと Broken link フラグが設けられている。 Closed GOP フラグはその GOP が以前の GOP の画面を必要としないことすなわち、 GOP の先頭の M-1 枚の B-picture は逆方向予測のみを使うことを意味する。 これは エンコード時に設定されるフラグである。 Closed GOP でないシーケンスを GOP 単位で編集した場合に、 結合部分の次の GOP の Broken link を立てないといけない。 デコーダは Broken link が立っている GOP では先頭の M-1 枚の B-picture は表示せずに棄てなくてはならない。(これも IS 段階で"棄ててもよい"に変った。)
スタートコードのあとに time code (25bit), closed gop (1 bit), broken link (1 bit) などが続く。
スタートコードのあとに、GOP の中の画像順を表す、temporal reference (10 bit), ピクチャタイプ の picture code type (3 bit), エンコーダがデコーダの仮想入力バッファの蓄積量を90 KHz クロックの時間で示す、 vbv delay(16 bit)のあと、動ベクトルが整数単位であること、 動きベクトルのフレーム間隔を P, Bタイプでは必要な個数記述する。 その他、 シーケンスや GOP ヘッダと同様であるが、extension や user data が続きうる。
スライスの垂直位置を含んだスタートコードのあとに、quantizer scale (5 bit)のあと、 extra information が続きうる。 スライス先頭では、Intra DC 予測値を 128 に、 MV の予測値をゼロベクトルにリセットする。
Intra DC は特別扱いされていて、独自の VLC を使い、それ以外の VLC は 2 次元 VLC である。 CBP によって落とされたブロックはブロックレイヤ自体がない。 そのため、ブロックの最初の係数に EOB が出ることがないため、 Non Intra の最初の係数の VLC の run= 0, level= 1 であるとき(DC 係数)は、 EOB と重複した符号になっている。
1990年 1月アイントホーヘン会合の統一の参照モデル RM0で、 フレーム構造が確定し、以降、参照モデル名を Simulation Model として 3月タンパ会合(SM1)、 5 月トリノ ad-hoc 会合(SM2)、 7月ポルトガルのオポルト会合(SM3)と参照モデルを改定、改良していった。
私自身は、MPEG-1 は 1989 年 2 月 Bellcore で行なわれた NJ 会議に参加したあと、 1989 年 11 月の久里浜では主観評価の評価者として参加した。 その後はオポルト会議からずっと参加しているが、 MPEG-1 の協調のフェーズの前半を見損なったわけである。 ポルトガルのオポルト会議では逆量子化について多少の貢献ができた。 サンタクララ会議では Block に MV を与える、 "8-Escape" と、MQUANT の効果が初めて確かめられたためその場で登場した Block に quant を与える "B-quant" の収拾に関与した。
1990年 9月のサンタクララ会合で技術的内容を固定し、 Video Committee Draft Rev.1 を作成。 その後、12月ベルリン会合、1991年 5月にパリ会合が行なわれ会議では、 1991年 9月の勧告をめざして、CD の表現上の修正と、 技術上の不適切さの除去そして、準拠テストの定義などが討議された。 ビットレートについては議論があったが、"upto about 1.5 Mb/s" としている。
MPEG-2 の議論は MPEG-1 と並行して 1990 年 9 月から始まり、 競争のフェーズのあと、1991 年 11 月の久里浜の主観テストの後は、 協調のフェーズとして、1992 年 1 月シンガポール会合で TM0、 3 月 Haifa会合で TM1、7月リオデジャネイロ会合で TM2, 12 月会合で、Draftの 最初の Version が作られた。
MPEG-1 の提案条件の一つには CCIR 601 を入出力と定めていた。 CCIR 601 フォーマットは NTSC であれ、PAL であれ、フィールドデータでできている。 多くの提案はこれを前処理と後処理として記述していた。 最終的にはこれらは標準化の外側の事としてしまったが、 動画像はほとんどがインターレースされたフィールドを基本構造に持っている。
MPEG-1 ではそれを考慮する符号化はできなかった。 その原因はビットレートの低さ ( 1.2 Mb/s の内、Video には1.15 Mb/s または 0.9 Mb/s 程度 ) にあったといえるかもしれない。
MPEG-2 では、NTSC や PAL 以上の画質を提供できる符号化を標準化しようというのである。 インターレースは予測構造と、符号化の中に取り込む必要があると予想されてきた。
画像は、Flower Garden, Table Tennis, Mobile \& Calendar, Popple という名の付いた標準画像である。各 5 秒間( NTSC 圏では 150 frame )の画像を 4 Mb/s と 9 M b/s ( Popple は 9 Mb/s のみ )で符号化した 7 種の再生画像を 1991 年 10 月 18 日までに提出した。
久里浜会合のホストである JVC はそれを乱数による順番にして、 A -- B -- A -- B の形で 2 回提示するための編集を行なった。 この編集作業のため 1 ヶ月の期間がとられた。
各社、各機関は 11 月 1 日には符号化アルゴリズムのアブストラクトと、 インプリメンテーション書類を提出し、 11 月 11 日には議長などに符号化アルゴリズムの完全な記述 Proposal Document を提出し、 11 月 18 日からの久里浜会合に参加者全員のための十分なコピーを持参して参加した。
久里浜会合は主観評価作業と、 implementation 評価そして、 アルゴリズムの verification 作業が並行して行なわれた。
この会合の終わり頃には主観評価結果が発表された。 そしてどのように収束のフェーズに入っていくかが議論された。
今回は前回の MPEG-1 のときのように Group 分けによるそれぞれの Group 内での Reference Model 作成には向かわなかった。 Video の議長はかなり慎重にその方向をさけ、言葉の定義 Rate Control などの標準化の外の枠組みからまとめにはいった。 "全般的な感想では、Frame based SM3 からスタートできるかも知れない"という Requirement group の議長の言葉が影響をあたえた。
そのため、ここではアルゴリズムの詳細には立ち入る ことはせずに、アルゴリズムの若干の分類を行ないたい。
まず、簡単に分類すると (1) 直交変換=DCT と、(2)それ以 外のサブバンド符号化、 ウェーブレット変換などにわけられる。
インターレース対応予測は大流行で、大半が対応した。 ところがこれにも考え方の根本的違いが表れ、基本的予測構造 をどうするかによって、 Frame を Picture とする、 (1) Frame based 予測構造と、Field を Picture とする (2) Field based 予測構造に大きく分けられる。
Frame based なら、field 予測をどのように導入するかに 工夫がみられ、field based 構造では多画像間の予測を 工夫することになる。
階層化による MPEG-1 との compatibility を保とうとする (1) compatibility 志向 と、(2) quality 志向にも大きく分けられる。 もちろん、主観評価で上位を占めるのは quality 派である のは当然であろう。quality 派は、インターレース対応を行ない、 compatibility 派は、それを嫌うという全般的傾向がある。
ところが、完全に MPEG-1 に則っていながら高画質の画像 を出したものがあり、これのもたらす影響は大きかった。 この社の使ったレートコントロールと量子化マトリックス は TM0 で使われることになった。
また、 B-picture を使わずに、良い画像を出した、ヨーロッパ の機関があり、implementation 上の負担が大きいという Implementation Group の意見もあって、B-picture の有効性 が疑われた。
(1) MC 予測と DCT 直交変換
これには標準化が保守的な技術に決まりやすいだけでなく、 DCT の符号化技術が長年の枯れた技術であるからであろう。 新しい技術は乗りこなすまで時間がかかるのである。 サブバンド符号化、ウェーブレット変換符号化も多数出現した。 Wavelet 変換がその新しさにもかかわらず優秀な結果を 示している例があった。
(2) B-picture の 有効性
implementation 上の負担が大きいことから久里浜では、 MPEG-1 で使われている双方向予測が問題になったが、 その次のシンガポール会合では片方向だけで良い結果をだれも示せなかった。 そのため、B-picture の 有効性を棄てさることはできなかった。
(3) Frame/field の適応的予測
インタレース対応は画質向上のためには必要と思われた。 ただ、Frame based SM3 からスタートするというのには field 派からの反発があった。 両者が妥協するのは困難にみえた。
そのため、シンガポール会合では Frame based 構造( MPEG92/080 )と Multi-field 構造( MPEG92/079 ) の 2 本だての TM0 となった。
422 to 420 と、Rate control は MPEG-1 のままで優秀な結果を出した、 ある社のアルゴリズムが採用された。これは標準化外の条件の決定である。
TM5 までこの手法は変更を受けなかったが、現在の Working Draft (Brussel version)ではサンプルの位置などについて (b) のように 記述されていたが、ソウル会合の Committee Draft では (c) の ように改められた。
 図 15 422 to 420 の色差サンプル位置
図 15 422 to 420 の色差サンプル位置
・Step 1: Target bit allocation
次の画面を符号化するまえに、その符号量を推定するもの。 I,P,B の画像を符号化するごとにその global complexity として、 X_I, X_P, X_Bを更新する。 S_{(I,P,B)} を発生 bit 数、 Q_{(I,P,B)} を平均量子化 パラメータ参照値とし、Bit_rate は [bit/sec]単位である。
X_I = S_I Q_I, X_P = S_P Q_P, X_B = S_B Q_B
X_I^{init} = 160 * Bit_rate / 115, X_P^{init} = 60 * Bit_rate / 115, X_B^{init} = 42 * Bit_rate / 115
GOP の中の次の画面の Target bit 数 T_I, T_P, T_B は次のように、 GOP の残りの bit 数 を I,P,B の残りの枚数の自分の picture type に 換算したもので割ることで得られる。
T_I= R /(1 + (N_P X_P)/(X_I K_P) + (N_B X_B)/(X_I K_B )),
T_P= R /(N_P + (N_B K_P X_B)/(K_B X_P)),
T_B= R /(N_B + (N_P K_B X_P)/(K_P X_B))
K_P, K_B は量子化マトリクスに依存する恒常な定数として、 K_P = 1.0, K_B = 1.4 が使われている。R は GOP に与えられた残りの bit 数 で、画面の符号化のあと、 R = R - S_{I,P,B}, GOP の最初の画面の符号化 ( I-picture )の前に R = G + R ( G = ( Bit_rate * N )/ Picture_rate ) をおこなう。 N_P, N_B は GOPのなかの符号化順で P, B-picture の残った枚数。
・Step 2: Rate Control
3 つの仮想バッファを使って、量子化パラメータの参照値を Macroblock ごとに
求める。i 番目の Macroblock の符号化の前に、I,P,B 各仮想バッファのフルネスを計算する。
d_i^P = d_0^P + B_{i-1} - T_P * (i - 1) / MB_Cnt
d_0^I, d_0^P, d_0^B は仮想バッファの初期フルネス、 B_i は i を含んで
それまでの全ての Macroblock の符号化発生 bit 数である。MB_Cnt は画面内の
Macroblock 数。画面の最後のフルネス値は同タイプの画面の符号化の
d_0^{I,P,B} として使われる。
つぎに i 番目の Macroblock の参照量子化パラメータをつぎによって計算する。
Q_i = d_i * 31 / r
ここで、"反応パラメータ" r は次の式で与えられる。
r = 2 * Bit_rate / Picture_rate
初期値は、
d_0^I= 10 * r / 31, d_0^P= K_P d_0^I, d_0^B = K_B d_0^I
である。
・Step 3: MQUANT
量子化パラメータの参照値を Macroblock ごとの activity によって変化させる。
Macroblock i の空間的 activity 測度として、その輝度サブブロックから intra
( original ) 画素値を使って、
act_i = 1 + MIN_{sblk= 1 to 4}( var_{sblk} )
ここで、
var_{sblk} = Σ_{j=1}^{64}(P_j - P)^2
P = 1/64 Σ_{j=1}^{64}P_j
P_j は画素値。正規化 act_i は次式によってもとめる。
N_act_i = ( 2 * act_i + avg_act ) / ( act_i + 2 * avg_act )
avg_act は act_i の以前に符号化した画面での平均。(MQUANT)_iは
次のようにもとめる。
(MQUANT)_i = Q_i * N_act_i
Q_i は step 2 で得られた参照量子化パラメータ。最終的に (MQUANT)_i
は [1, 31] に制限される。
この Rate control の知られている制限として、 (1)Step 1 はシーンチェンジを余り効率良く扱わない。 (2)すべての処理に現在は frame macroblock を使っているから、 Step 3 は強くインターレースされた素材ではうまく働かない。 (3)シーンチェンジ後に Step 3 で使われる avg_act は間違ったものとなる。 (4)VBV は保証されていない。 が挙げられている(MPEG92/077)。
この TM0 のレートコントロールへの評価は高い。 ただし、Step 3 が SNR を大きく 低下させるため、SNR で評価したいシミュレーションとしては何が起こっているか 把握しにくい面も指摘されるため、Step 3 を使わない人も多い。
後のロンドン会合では Frame/field 対応を考慮して、 Step 3 の アクティビティ 計算を修正し、Block の AC パワーを Frame/field 型で 8 種類として、その中 から最小値をとる方法が提案されたりした。 次に述べる、実際に使われる Frame/field 予測と Frame/field DCT は独立であり、 予測誤差の量子化に Intra の activity を使うという仕組みはかなりの矛盾 を含んでいるのも事実である。
私がこれを修正したい点としては、 (1) Step 2 が 3 つの仮想バッファを使う理由が明確でなく、I, P-picture と B-picture の量子化の粗さの比率である、 K_B は 3 つの Buffer の内の B-picture 用のバッファ量の初期値の他のバッファの初期値との比率 として与えられているが、それは長いシーケンスでは保たれない 恐れがある。やはり SM のレートコントロールのように 1 つの 仮想バッファ量からの感度として K_B を使うべきであろうと思う。 (2) Step 3 の N_act の 式で変化できる範囲は 0.5 - 2.0 であるがこの範囲は もう少し広い方が良いようである。
Macroblock layer に 予測の切り替えを示す bit が用意され、 frame 型の予測か、 field 型の予測かが切り替えられる。 interlace_motion_type という 1 bit の flag がそれであった。
frame 型では Macroblock に 1つの MV がつかわれ、field 型では 2 つの MV が Macroblock 内の 2 つの field にそれぞれ使われる(図 16(a),(b))。
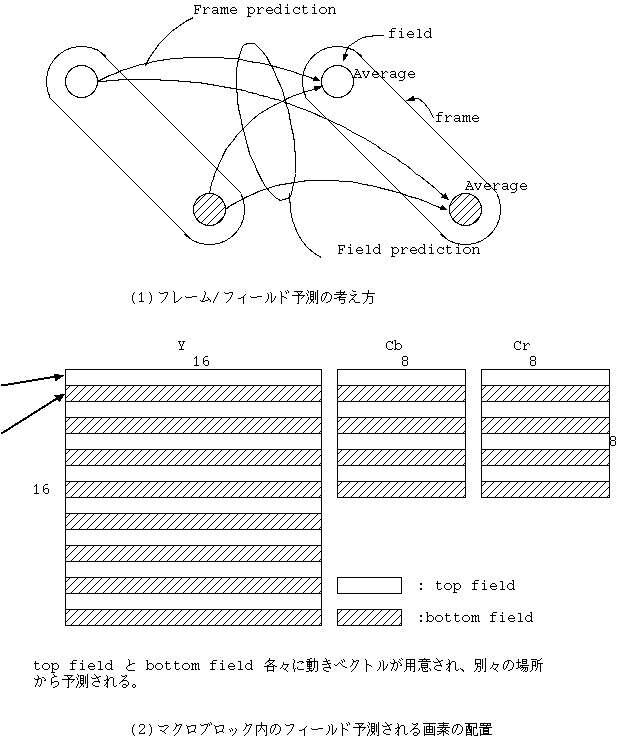 図 16 フレーム/フィールド予測
図 16 フレーム/フィールド予測
動きベクトルは frame 内の動きベクトル表現であったが、frame 型予測用 MVと field 型予測用 MV で、垂直方向の半画素の計算方法が違うようになった。
frame 型の縦方向 half pel では、MPEG-1 を frame に適用した場合と同じく、 隣接する even field と odd field の平均で作られる(図 21(a))。 それが、field 型 縦方向 half pel では 各 field の中での half pel が取られる。 たとえば、even field 内 2 ラインの平均となる(図 20)。
Frame/field 予測のいずれを使うかのエンコーダ側の判断は Frame 優先の MSE 判断で行なう。 B-picture では field 予測は両 field について同じ方向(前、後、内挿)に制限する。 このことにより、Macroblock typeは MPEG-1 のままにしておくことが可能となった。 field 型予測が B-picture で使われるときは、Macroblock に最大 4 つの MV が使われる。
色差は MV の値を 1/2 にして行なうのは MPEG-1 と同じであるが、 色差もインターレース画像であるので、 field 予測のときは 8 x 4 の 2 つの field への予測を Cb, Cr にそれぞれ行なう必要がある(図 16(b))。
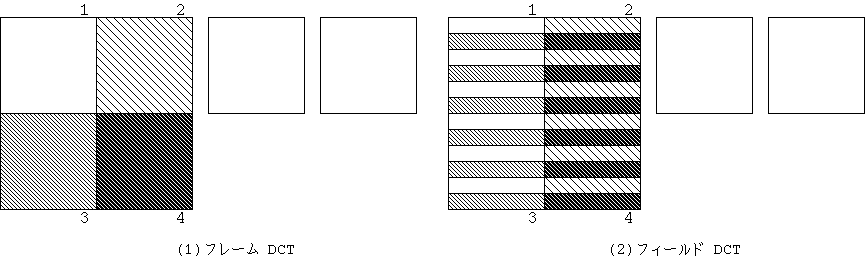 図 17 フレーム/フィールド DCT
図 17 フレーム/フィールド DCT
Frame/field DCT のエンコーダ側の判別法も次のように規定された。 これは Macroblock の輝度の縦方向の最高周波数パワーとその半分の周波数 のパワーの比較に基づく判定である。(ただ、この判別方法は あまり良くないということがわかり、リオ会合で改良された。)
Field DCT が、(frame DCT でなく)用いられるのは Var1 >= ( Var2 + 4096 ) のときである。
Var1 = Σ_{i=0}^{15}( Σ_{j=0}^{15}C_j^1 X_{i,j} )^2,
C_j^1= { 1, -1, 1, -1, ... }
Var2 = Σ_{i=0}^{15}( Σ_{j=0}^{15}C_j^2 X_{i,j} )^2,
C_j^2 = { 1, 1, -1, -1, ... }
それ以外には、field based TM0 では multi-field の構造が提起された。
これは静止領域には frame based が有利で、 動領域には multi-field
構造が有利であるからである。
その他のすべての提案は "Core experiment" として TM0 からの 対照実験が要求された。基本的に 2 社以上が独立に全く同じ結果を出 さないかぎり受けいられないとする。シンガポール会合で挙がった Core experiment には次のようなものがあった。
Modified quantizer、 Full search MC、Half pel refinement from rec. img.、 Multi-field/Adaptive frame coding、Scalability、Field base option、 Compatibility、IBP,IPP',,,( P' とは Non Recursive P-picture の意味)、 Non DCT、Overlapped MC、Adaptive VLC、Cell loss。
Sequence layer に Pure-field 構造 のフラグと、422 のフラグを設ける。 Pure-field では A 社の提案するシンタックスに切り替わる。 422 では 8 つの Block が MacroBlock となり、 CBP は暫定的に固定長の 8 bitとした。
Pure-field でないとき、Picture layer には Multi-field 構造/Frame based 構造のフラグが付け加わった。
Frame based 構造 とは picture が frame である TM0 と同じ構造である。
Multi-field 構造 では 一つの Picture header のあとに、2 つの Field が 並ぶ。Picture は field であり、Macroblock は 16x16 としている。 後ろの field は前の field を予測につかうことができる。
Frame based 構造 のときには Macroblock layer にあった、TM0 の interlace_motion_type という 1 bit の flag が変わって、 2 bit のコード ( 00: Frame, 01: field, 10: FAMC, 11: Dual field )となった。 最初の 2つは TM0 からのもので、Frame 型の予測と field 型の予測である。
FAMC ( Field Adjusted MC )とは B 社提案の Frame base 予測のやりかたで 剛体の平行移動をインターレース構造に適用したものである。 動きベクトルは 1 つでありながら、両方のフィールドからの精密な予測を行なう ことを目的にしている。
Frame 型予測の動ベクトルを x 方向は各 field 間隔に換算して半画素まで 適用し、 y 方向は同パリティの field の半画素位置への線と平行線距離で 最も近い逆パリティの画素値を同パリティへ投影してから距離による線形内挿をするもので、 小さい垂直方向の動きに対して効果がありそうで、 横方向にははっきりと動いているが、縦方向にはクリティカルな動きをする、 Flower Garden では 1.5dB 向上するという結果が出てきた。 その他の標準画像では 0.数 dB しか変化しない。
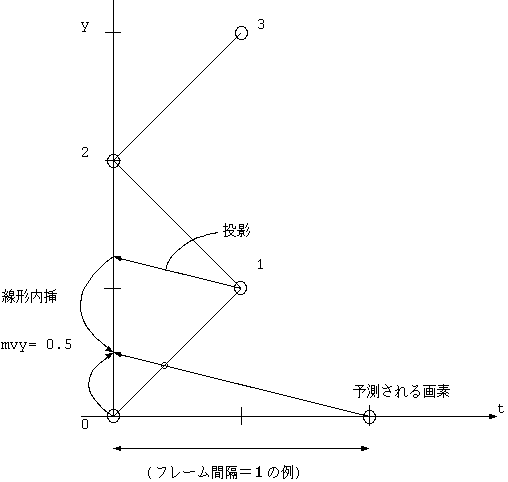 図 18 FAMC (Field Adjusted MC)
図 18 FAMC (Field Adjusted MC)
 図 19 Dual Field の概念図
図 19 Dual Field の概念図
Multi-field 構造 では, interlace_motion_type は、 通常の field 型の 予測と、Dual field 予測との切替を示す、 1 bit となる。
TM1 は TM0 をさらに複雑にしたがこれは比較のためのシンタックスであるといってよく、 次の会合ではきっと簡単化されるであろうと期待された。
Rate Control について、TM1 では初期 ave_act = 400 ( 400*64の誤り? )と規定して、 最初の I-picture から MQUANT 変化が付けられるようにした。また、step 1 の Q_{(I,P,B)} を実際に使用された量子化値 ( MQUANT_i ) の平均とした。
422 to 420 について、色の field 型予測に輝度と逆側のパリティの画像が使われる問題 が指摘され、 TM1 では色の field 型予測では輝度と同じパリティを使うよう指定した。
Frame/field 予測と Frame/field DCT のそれぞれの効果がかなりあること が検証された。そこで、Frame/field MC と Frame/field DCT の Coupling (連結) が議論された。独立にフラグを与えたのは実験のためで、その効果は +0.1 dB 位しかない。デコーダの複雑さはそれによってかなり増加している とみられ、これを単一のフラグにするべきであるという意見があった。 反対意見 もあり、シンプルなエンコーダは Frame 予測しかできないけれども、 Frame/field DCT は使いたいというのである。結論は出ずに終わった。
再構成画像からのハーフペル MVD はほとんど効果がないということも 多くの実験結果がでたが、TM の記述の変更はされなかった。
・1992 年 11 月 1st Working Draft
・1993 年 3 月 2nd Working Draft ( Frozen technical spec. )
・1993 年 11 月 Committee Draft 投票
・1994 年 11 月 IS 化終了
ハイファ会合ではさらに、以下の 3 つの課題が MPEG の将来をきめるものとして 各国に持ち帰り議題となった。
動画像符号化の技術的観点からは HDTV も CCIR 601 と同じく、インターレースであり、 そこに新規の技術を必要としないという意見もあり、どのように推移していくかが注目された。
Coding と Loss Less は同じアルゴリズムで bitrate がある値を越えると Loss less になるような "連続性" をもつべきであると思うが、H.261, MPEG-1, MPEG-2, は DCT を 使っているため、 Loss less への連続性はない。 静止画符号化の JPEG でも Loss less Coding を含んでいるが DPCM 程度であり、 DCT を使った通常の Coding とはまったく隔絶したアルゴリズムになっている。
入力画像から再生画像を引くという、フレーム間予測の構造は、 誤差を伴う符号化に特有の基本的構造であり、Loss less coding では入力画像どうし の引算でよい。つまり、Loss Less Coding ではエンコーダはデコーダを含む必要がない。
動き補償は、 Loss Less Coding にも有効と思われる。 この部分は DPCM と同じく、( 時間方向の ) 相関を利用した予測であるから、 誤差を符号化する点で通常の Coding と違いはない。誤差パワーを減少させるだけの 機能とすると、 B-picture も有効かもしれない。これには多少の疑問が残る。なぜなら、 B-picture の有効性は量子化と絡んではじめてはっきりとしているからである。 ただし、 I,P-picture と B-picture との量子化特性を変えなくても、B-picture は有効 という結果もでている。
そうしたら次に、空間方向の相関を利用した直交変換は有効だろうか ?という質問がでる。 低振幅の広がった値を DCT などによって小数の低域係数に集中させることは Loss less でも有効な符号化技術に思える。多くの小振幅の数値よりは、少しの大振幅 係数のほうが符号は小さい。数値の表現符号長は値の Log に比例するからである。
DCT はどうして Loss Less に使えないかを考えてみると、 IDCT ミスマッチのところで述べたが、逆量子化で奇数をつかうと決めているため、 step size = 1 はつかえないのである。 step sizeの 最小値は 2 である。 Loss Less では量子化自体がないため、これは step size= 1 をつかい、奇数への制限が なくなるとIDCT ミスマッチが頻発するわけであり、IDCT ミスマッチ問題の別種 の解決が必要となる。 IDCT ミスマッチは入出力は整数であるのに DCT が実数演算であることである。 これが原因で Loss Less Coding への連続性が閉ざされているなら、 整数型の DCT である ICT を考慮するべきであろう。
さらに、量子化係数の範囲は H.261 では +-127 MPEG では +-255であった。 +-2048 まで表現できないとクリップされるので、表現方法を変更する必要がある。 run-level の 2 次元 VLC も恐らくそのままでは有効性に疑問がある。 zero run が そんなに続かないだろうからである。 応用面は、スタジオでの放送素材蓄積などが挙げられている。
米国 の National Body (USNB) の提案は今回、日本を除く各国の賛成を得た。 米国は 10 Mb/s 上限は HDTV となんの関係もないと言い続け、10 M上限が 取り払われることに専念したことが効を奏した。 日本はスケジュールに変化をさせないという条件付きで認める態度に出た。 すなわち、日本のメーカーは MPEG-2 のスケジュールが遅れることを一番に 恐れているのである。ヨーロッパは遅延にたいして気に止めない。むしろ遅れて くれたほうが技術的な立ち遅れの解消につながるとみているかもしれない。
この問題はやはり ATV がらみの米国の国内問題であるが、ATV は世界的に 影響を与えることになろう。次世代テレビジョンが、完全にディジタル符号化 によって放送され、視聴者はディジタルデコーダを各 TV システムに備えるの であろうか。 ATV の 6 つの提案方式の内、大半 ( 日本の Muse (地上波向け) と、ヨーロッパの方式以外)がディジタル方式で、しかもほとんどが DCT 符号化方法をとっているという。この方が Muse をはじめとする伝統的な アナログ帯域圧縮によるものよりは優秀であることはおそらく事実であろう。
Requirement の会議と Head of Deligation の会議で行なわれる、政治的 な会議は 3 月に固定したはずの Requirement 書類の修正を行なった。 外向けの informative な書類には HDTV の文字がでている。内向けの mandatory な書類にはそこまで明確な修正を行なっていない。
HDTV の Subjective Test については 1993年 3 月技術凍結以降に HDTV 符号化確認 が行なわれる。
今回の MPEG 資料に 6 方式のひとつ AD-HDTV の概略が示されていた。 TCE Los, 北米 Philipsなどが 92 年 6 月半ばに Prototype として、MPEG-1 のままで、17.72 Mb/s で HDTV を符号化したようである。
その準備のための最初の ad-hoc 会合がリオ会合の中で開かれた。これには 2 年程度で標準化するのか 5 年程度の期間を標準化にかけるのかで使える 技術が全く異なってくる。
短期的にとらえると、 H.261 の簡単化か修正程度になるし、中期的なものなら より高度な技術が登場する余地をあたえる。 8 kb/s 程度の符号化は VQ を経験する日本のメーカーのお家芸であろうという意見も聞かれた。
さらに、"forward_reference_fields" と "backward_reference_fields" という各 2 bit の予測の参照画像の性質を示す同様な意味合いの 項目がつけられた。
この Picture layer の記述によって、さまざまな構造が可能になる。 たとえば、I,P,B がすべて Frame 構造では、これらにすべて "11" を使う。
B のみ field の構造では B-picture の picture_structure は field をとり、 予測は順方向予測が両 field からであったり、片 field からであったりができる。 自身が field であって、 予測を両方の field に指定するのは両方の field から選択する 場合と、 Dual-field 予測( 1 field の 予測に 2 つの field の予測の平均をつかうもの) をつかう場合である。
I-frame を分離して I-field と P-field にする場合は、 P-field は I-field のみ を予測の参照につかう。自分が "10" なら、 forward_reference_fields は "01" である。
I,P,B すべてが field の Pure-field 構造もこの記述でかなりの程度、包含できる。 たとえば、 B-picture の参照 field 数 R= 3 では前方と後方の参照に "11" を使うことで対処できる。両方向とも "01" または "10" では R=2 の Pure-field 構造 が実現できる。しかし、 P-field と B-field の Frame は存在できない。 4 つの参照 field は frame 毎にしか変化できないからである。
以上のようにこれによって、懸案のフレーム構造とフィールド構造の問題(確執?)が かなり解決したといえる。シンタックス上の問題なく、field 構造が取り入れられ、 量的に把握されるようになった。また、次の動きベクトルの表現の変更によって field 予測時の非効率さも解決した。
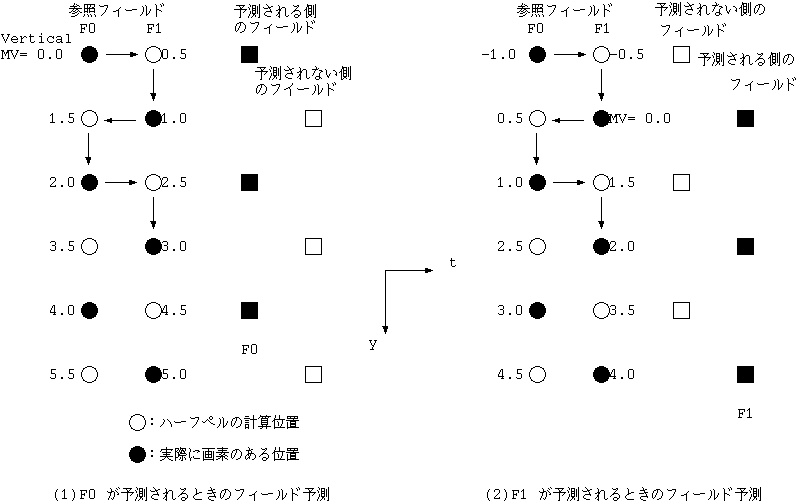 図 20 TM0 のフィールド予測の y 座標
図 20 TM0 のフィールド予測の y 座標
また、どちらの field かが明確であるベクトルも Frame 全体をさす非効率さをもっていた。 TM2 からは、 field の動きベクトルの y 座標は field 内に閉じた数を用いる ことになり( 図21(b) )、その前にどちらの field からかを示す 1 bitが forward ( or backward)_field_reference = "11" のときにのみ付けられるというふうになった。
こうすることで複雑になるのは MV の予測である。field の MV の Y 座標は 2 倍して 予測値とし、予測値は 右シフトして差分をとることとなった。 なお、Frame 予測の動きベクトルは TM0 から TM2 (図 21(a)) で変化しない。
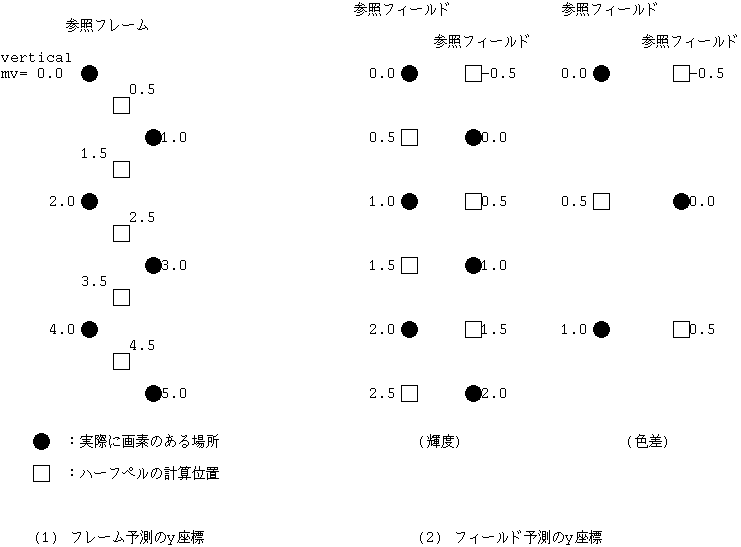 図 21 TM2 のフレーム予測とフィールド予測の y 座標
図 21 TM2 のフレーム予測とフィールド予測の y 座標
予測について 9 種の Core experiment が次回会合までに実験するものとして予定された。
・Simplified FAMC ・SVMC ・DUAL-PRIME ・Global Motion Compensation ・Leaky Prediction 1 ・Leaky Prediction 2 ・Reverse Order Prediction ・Simplification of Test Model ・16x8 Macroblock
FAMC の B-picture での内挿予測は implementation group から禁止された。 通常の Half pel 予測はフレームメモリーからの画素アクセスを 4 倍にはしない。 それは Macroblock の単位で、 17x17 画素をアクセスするだけでよい。 ところが、 FAMC では 両 field 用の縦方向のずれが大きい場合があり、約 2 倍の メモリーアクセスが必要とされることが明らかにされた。 Simplified FAMC は画素内挿精度を 3 bit に制限し、さらに B-picture の 内挿予測 では使わず、 さらに動ベクトルサーチも簡単化したもので再度提案された。
Frame structure での Dual field は性能の低さから消え去った。dual の改良版 dual' (prime とよむ) が提案された。これは、 Macroblock に 1 つの動ベクトルと、 field 間隔による換算との差分ベクトル[ -1, 0, +1] だけを許すものである。
・Dependent Scanning
Frame/field DCT の Mode で、 Zigzag sccanning と他の
scanning ( CMTT scanning など)とを切り替えるもの。
・Independent Scanning
MB に 1 bit 付加 bit を与えて、 scanning を Zigzag と
Vertical scanning とを切り替えるもの。これで 0.2 - 0.3 dB の向上例はある。
・Downloadable Quantize Matrix
Picture layer にその使い方を示す table をつけて 4 つの QM を download するもの。
Intra/Nonintra, Frame/Field, Y/C の 8 種の mode に、どの QM を使うかの 2 bit を
つけるので 16 bit 付加である。
・Adaptive Control of Matrix Selection at MB Level
MB に 2 bit を CBP のあとに付加して 4 つの QM を適応的に切り替えるもの。
・Increase Range of Transmitted Coefficient
・Increase Precision of DC Coefficients
・Extend Range of Mquant
・Block Adaptive Quantisation
・Non-8x8 DCT
・Alternate DCT (DCT/NTC)
その他、 Compatibility/Spatial Scalability に 7 種、 Low Delay に 3 種、 Frequency scalability に 10 種の実験が予定された。
ad-hoc 会合とはいえ 120 名も参加した ニューヨーク会合は、メンバーにとっては目新しい ATV (米国の次世代(地上波)放送)の技術が紹介された。これは技術的検証をへて 初めて受けいられるべきもので、重要とされる技術は Core Experiment として 複数機関の実験が薦められた。ATV の提案機関 AT\&T と GI は協同で、いくつかの 技術を導入してきた。
そのなかで、特筆すべきは、 "VQ" という名でよばれるスキャンのマスクパターンを もちいる符号化である。これによって Run 長をへらし、1次元 VLC による符号化を 行なう。提案者の言によれば、"20 %の符号量削減" ということで、もしこれが本当 なら大変な技術であるということで話題になった。しかし "VQ" は多くの機関が実験 を行ない、総じて否定的実験結果をロンドン会合では提出されることになる。
それ以外にも 8x8 毎に MVを用意すること、8x8 毎の Intra/inter 切り替えが提案された。 これらも Prediction ad-hoc Group では否定的結果が提出されたという。両者が 協同で提案してきたのは、 米 Cable lab.の仲介があったという。 全米の所帯数の 60%-70% が使っている CATV の後押しによる ATV 符号化技術の提案は MPEG にとって 興味深いものであった。総じて放送業界が関与してくるのは歓迎する空気があるが、 このように否定的な実験結果が出されていくと MPEG と ATV の関係が心配される。
ロンドン会合はリオの後のはじめての正式会合であり、190 名の参加があった。 ニューヨークから 1 ヶ月しか経っていず、実験結果の提出のみによって処理を行なわなければ
ならない。詳しい検討がなされる暇がほとんどなかったが、 "VQ" の結果が明確にで たことと smart prediction が確定したことが、大きなことであったろうか、 (しかしその後、 ローマ会合で、SVMC は消え、 Dual prime のみになった。) Requirement Group から "Profile" の定義がだされ、" Core Profile" の定義が 始まったことも大きい。そして MPEG-1 の IS 化がされた。これについては後述する。
高級な予測手法(smart prediction)が比較され確定されていった。 TM2 の段階で FAMC は単純化され、Simplified FAMC (SFAMC)と呼ばれた。 メモリバンド幅の制限から、B-picture の内挿予測で使用せず、内分の精度は分母を 8 とし、動ベクトル探索も簡単化された。ニューヨーク会合の結果は FAMC は B-picture の 内挿予測での禁止で性能がでなくなり、それ以外の高級な予測手法が定義され、比較された。
Dual'(Dual Prime)と、SMVC である。 SVMC とは、Frame picture では、FAMC, Same parity, Near field, Modified Dual の 4 種、 Field picture では、 FAMC, Same parity, Diff. parity,Modified Dual の 4 種を 切り替えて使うもの である。
ニューヨーク会合ではこれらがマージされ、結果的にはロンドン会合で、 SVMC3 ( Same parity, Near field, Dual field )がプライム型 ( マクロブロックに1本の MV に(-1,0,+1)の差分ベクトルをつける形 )になった。 これに、 Dual' が付け加えられ、Modified Dual がなくなった。 つまり暗号的にかくと、
Smart prediction= SVMC3' + Dual' - modified dual
となって smart prediction は固定された。(と、この時点では考えていた。) Smart prediction 自体が使われるかどうかは、Video 全体会合にまかされ、 Implementation Group の Hardware 量の見積が 影響することとなり、予断はできない状況である。
(2) Global MC
I-picture で、2つのフィールド間の動ベクトルを Picture layer に記述するもの。 サポートする他機関がないため消滅した。
(3) Leaky Prediction 1
ループ内フィルタによる、AC 高域成分の低下を予測時に行なうもの。 整数 pel に[1,14,1]/16, half pel に[-1,9,9,-1]/16 これは AC のみ減衰する。 整数 pel に[1,12,1]/16, half pel に[-1,8,8,-1]/16 これは DC も減衰させる。 支持者なし。改善は有意でないとして Core Exp. から脱落。
(4) Leaky Prediction 2
128 との 差について LF= (1-2**n) を掛けるもの。 AC, DC とも影響する。 n= 3 が使われると、予測値を 7/8 程度に減らして用いることになる。 Prediction Group は Intra slice/column を支持。 ATM Group に移管。
(3),(4) は通信用であり、I-picture を使うと、Buffer での遅延が大きくなるため、 I-picture を用いない符号化を考えるものであるが、I-sliceまたは I-columnという 別の解決方法と比較して、SNR は良いが独特の雑音が発生するということがわかり、 (4) には乱数を混ぜる解決方法までが提示されていた。これらは予測の精度を落とす 方向の技術であり、(1) とは逆の方向である。
(5) 8x8 Intra/Inter, 8x8 MV
両者はニューヨークで提案され、ロンドンで、否定的結果をえたが、両者を組み合わせたもの が Core Exp.として生き残った。
(2) Dependent scanning
Frame/field DCT のモードを使って 2つの scanning を切り替えるもの。肯定的結果
があったが、効果が小さいことが問題であった。結論は出ていない。
(3) Independent scanning
ニューヨークで Zigzag/vertical は Inverse Scanning によるエンコーダ側の判定方法が提示
された。ロンドンでは、Zigzag/vertical scanning は Frame only coding には効果
がある(符号量削減が 10 % 程度)ことが示されたが、 Frame/field 予測かつ Frema/field
DCT のもとにおいては効果が最大 5 % 程度であるので、一度 "Drop" と議長は書いたが、
Video 全体会議では結論がでなかった。
(4) DC 精度
MPEG-1 では Intra DC の量子化は 8 ( 8 bit)となっていたが、それを、 4, 2, 1
(9/10/11 bit) に拡張する案がロンドン会合で採用された。
(5) AC 係数精度
量子化 AC 係数は MPEG-1 では +- 255 に制限されていたが、これを +2047 - -2048
まで拡張する案がロンドン会合で通った。Escape + run + level の level が 12 bit
になる。MPEG-1 の 2 段階の escape が複雑であり、単一の 12 bit にする単純化になる。
(ただし、逆量子化の掛け算の乗数の幅が広がる。) なお、(4)(5) は High Quality
対応である。
(6) 非線形 MQUANT
MPEG-1 では、MQUANT は 1 - 31 の線形であったが、31 種を非線形に割り当てる
事になった。詳細はまだ、修正されるが( 1/4, 1/8 の level (* 印)は除か
れる可能性が高い) ロンドン会合では、以下の表のようなものである。
表 13 非線形 MQUANT
| 0 | +1 | +2 | +3 |
0 | 0.5 | 0.625* | 0.75* | 0.875* |
4 | 1 | 1.25* | 1.5 | 1.75* |
8 | 2 | 2.5 | 3 | 3.5 |
12 | 4 | 5 | 6 | 7 |
16 | 8 | 10 | 12 | 14 |
20 | 16 | 20 | 24 | 28 |
24 | 32 | 40 | 48 | 56 |
28 | 64 | 80 | 96 | 112 |
(8) 8x1 DCT
縦方向の DCT を行なわないで符号化するモードを持つことで、
インターレース対応の意味と共に、テロップ文字などの明確さをだすことが目的である。
(9) NTC( Non Transform Coding )
テロップ文字などを明確に出すために、 両方向の DCT を行なわないモードをもち、
量子化と DPCM を行なうこと。
(8), (9) は一部同じ目的を持っており、 DCT 符号化の欠点を補う意味で、 Core Experiment となっている。
この投票に米国とフランスが反対を表明したが、反対理由のコメントはすべて処理され、 反対票はなくなった。米国の反対は Decoder の精度に対する規定を、 Video part から削除し、Compliance (準拠)の part に移し、精度を満たさない decoder は そのことを記述するとのみすることを要求するもので、 IDCT の精度を含めた Decoder の精度を実質的に緩めたことになる。
Bitstream の質を保つために、Encoder の中の local decoder の精度は高い必要が あるが、Decoder の精度は完全でなくとも良いということであり、安価な Decoder や、 Software Decoder での速度が足りない場合の手抜き処理を許すことになる。 いい加減な Decoder が出回ることは MPEG 標準の能力を誤解させる可能性があるが、 それらを許さないことで、もっと質のわるい非標準が広まるのは避けるということ であろう。
フランスの反対理由は 12 Hz, 12.5Hz, 15Hz 等、それまでの 1/2 の Picture Rate を Picture rate の項目の 空き ( "reserved" ) になっていたところへ入れるよう に要求するものであった。こちらはほとんど空のピクチャーを使うことができる という議長の説得にフランスは妥協した。
米国とフランスの両者とも、 Software Decoder の方向を示しているのかもしれない。 フランスのある書類では、486 の 33MHz で CIF が 12.5 Hz で動作するという。 また、非標準のマルティメディア動画が出てきている事への対応かもしれない。
そののち、 11 月 25 日には MPEG と直接関係のない Calfornia 大学 Berkeley 校 から、かなり優秀な Public Domain Software (PDS: 無料ソフト) である、MPEG-1 の Software Decoder ( version 1.2 ) が出てきた。この PDS は UNIX の多くの Workstation で実行でき MPEG-1 の bitstream file をあたえるだけで、再生画面 を Xwindow に表示する。 256 色には 2x2 のディザ表示、モノクロのディスプレイ にもそれなりに表示をする。
C 言語のソースはかなりの品質になっており、MPEG 標準の Decoder として完全か というと、逆量子化と IDCT 精度には問題を見つけているが、通常の使用にはほと んど問題ないものといえる。MPEG-1 のエンコーダ、デコーダを勉強している人には かなり参考になることとおもう。UNIX のネットワークで、WIDE 回線に加入している 大学等では ftp を使って入手可能である。( toe.cs.berkeley.edu (128.32.149.117) の /pub/multimedia/mpeg/mpeg-1.2.tar.Z. )
Software Decoder の利点は、Hardware を購入する必要がないだけでなく、MPEG-1 標準 の Bitstream を 標準の Xwindow 上で扱えることで、マシンを横断して動画 再生を行なうことである。ただ、マルティメディアコンピュータは動画再生の主流ではな く、そのはしりにすぎないと私自身は考えている。まじめな仕事場はエンターテイ メントに使うには高価すぎる。Workstation で動画を表示するのは現在物珍しいだ けであり、"家電" が最終的に動画符号化の落ち着く場と思う。
とはいえ、筆者は R4000 を CPU にする 70 MIPS のワークステーションを仕事に使用 していたが、この Software Decoder は 160x120 ぐらいの小さい絵では、 22 Hz でビュンビュン動画表示する事に驚いてしまった。 SIF (352x240) の画面 サイズでは 7 Hz 位であり、まだ不満が残るが Workstation の速度は年々倍加 しており、Software Decoder の速度は放っておいても向上するはずである。
非標準のマルティメディア動画がでるのは、一方では MPEG-1 の標準があまりに 難しくて、複雑である面も理解する必要があると思う。 MPEG は重たい、X も重たい。 それらを避けて通りたいのも理解しなければならない。 MPEG のシンタックスは必要 以上に複雑ではないか。MPEG-2 ではシンタックスの単純化が最終的に議論される予定 であるが、それとは別に DCT は計算量として重すぎると、私を含めて誤解して いたようである。
8x8 の 2 次元 IDCT は 式どうりの 1 次元 DCT を 16 回用いる方法では 16 x 64 の積和計算が必要となる。これは画素あたり、 16 回の積和になり、 SIF 画面 30 Hz では画素レートが 352x240x1.5x30 であるので、61 MIPSの 積和計算、積と和を別に数えると122 MIPS が必要となる。これではとても 現在の Workstation では実行できない。だがこの計算量はかなり減らせる のである。これには次のようないくつかのアプローチがあるが、すべて ソフトウェア向きである。
・P, B-picture では Not Coded の ブロックが多く、 IDCT の必要なブロックは 全体の一部である。Not Coded のブロックは IDCT を行なわないだけで、 デコーダの IDCT 量は何分の 1 かになる。
・2 次元 IDCTを使うと係数の 64 倍の積和回数で IDCT ができる。これは 平均非ゼロ係数の個数が 16 個未満である場合に計算量の削減になる。 実際の Coded ブロックあたりの平均非ゼロ係数の数は 5, 6 個であるため、 非ゼロ係数の個数の小さいブロックは 2 次元 IDCT を用いることが有効となる。
・高速 IDCT アルゴリズムは多くの研究があり、その使用により、8 点の 1 次元 IDCT の 乗算と加減算の回数はかなり減らせることがわかっている。 式どうりの計算では 64 回の積和となるのに対して、文献(6) によると乗算 11 回、 加減算 29 回にまで減らすことができる。
この Software Decoder の使っている IDCT の ルーチンは Thomas G. Lane の作で、Independent JPEG Group の software の一部であるという。 高速化アルゴリズムは 12 回の乗算 と 30 回の加算で 1 次元 IDCT を行なう ものであり、文献(6)を挙げている。これだけで、 64 回の積和からみると 1/5 以下になっている。それだけでなく、このルーチンは 1 次元 IDCT の 係数のゼロにあわせて処理内容を変えることで、さらに 50 % ほどの高速化 を行なっている。また、 非ゼロ係数が 1 個だけのときは 2 次元 IDCT を使っている。
この Software Decoder は、IDCT 以外の部分ではさほどでもないが、特に IDCT については、ぎりぎりの最適化を実現しているようである。I, P, B-picture を含む Bitstream での分析ではデコード処理の大半 ( 90 % 近く) は IDCT 以外の部分となっている。こうしてみると、DCT は決して重たいわけではないといえるし、もっと高速な MPEG Software Decoder が出てくる可能性はまだまだあるといえる。ただ、これほどの Decoder が全くの無料で提供されるなら、よほどのものでないと売り物 にはできない。
X_j = √(2/8) Σ_{i=0}^{7} C_j x_i cos[j(2i+1)π/16]
C_j = { 1/√2 ( j= 0 )
1 ( else )
いま求めるのは、 X_j の 2√2 倍とし、それを y_j とする。
y_j= 2√2 X_j= Σ_{i=0}^{7}{ c_{i,j} x_i },
c_{i,j} = √2 C_j cos[j(2i+1)π/16]
c_n = √2 cos[nπ/16] とすると、c_{i,j} は次の表で表される。 この表を眺めるだけでその規則性から計算が削減できることがわかってくる。 たとえば、 j= 0, 4 は加減算のみで計算できるし、 j が偶数であれば、 i= 0 と i=7、 i=1 と i= 6 などの係数が同じであり、 j が奇数であれば、それらは符号だけが反転し ていることに気がつく。それらは先に加減算を行なってから乗算する。以下、このよう な規則性の利用をたどっていくだけで高速 DCT アルゴリズムがほとんど説明できる。
表 13 DCT 計算の定数 C_{i,j} の値
i\j | 0 1 2 3 4 5 6 7
0 | 1 c_1 c_2 c_3 1 c_5 c_6 c_7
1 | 1 c_3 c_6 -c_7 -1 -c_1 -c_2 -c_5
2 | 1 c_5 -c_6 -c_1 -1 c_7 c_2 c_3
3 | 1 c_7 -c_2 -c_5 1 c_3 -c_6 -c_1
4 | 1 -c_7 -c_2 c_5 1 -c_3 -c_6 c_1
5 | 1 -c_5 -c_6 c_1 -1 -c_7 c_2 -c_3
6 | 1 -c_3 c_6 c_7 -1 c_1 -c_2 c_5
7 | 1 -c_1 c_2 -c_3 1 -c_5 c_6 -c_7
a= x_0 - x_7 a'= x_0 + x_7 b= x_1 - x_6 b'= x_1 + x_6 c= x_2 - x_5 c'= x_2 + x_5 d= x_3 - x_4 d'= x_3 + x_4
e = a' - d' e' = a' + d' f = b' - c' f' = b' + c' y_4 = e' - f' y_0= e' + f' y_6 = c_6*e - c_2*f y_2= c_2*e + c_6*fc_6/c_2= √2 -1, c_2/c_6= √2 + 1 であるから、y_6, y_2 は、 つぎのように 3 回の乗算と 3 回の加算で求められる。
g = e - f h = √2 * f y_6 = c_6*(g-h) y_2 = c_2*(g+h)
x' = a * x + b * y y' = c * x + a * yの形の計算は、
z = a * ( x + y ) x' = z + (b-a)* y y' = z + (c-a)* xとすることで、3 回の乗算と 3 回の加減算にすることができる。 ( (b-a), (c-a)は定数なので計算量に数えない。)
y_1 = c_1*a + c_3*b + c_5*c + c_7*d y_3 = c_3*a - c_7*b - c_1*c - c_5*d y_5 = c_5*a - c_1*b + c_7*c + c_3*d y_7 = c_7*a - c_5*b + c_3*c - c_1*dまず 2 x 2 の行列 ( c_n ) を、
( c_n )= √2 ( cos(th) -sin(th)
sin(th) cos(th) )
th= nπ/16
とする。そのとき、奇数係数は次のように表せる。
なお、表示の都合で縦ベクトルも横に書く。
(y_3, y_5)= ( c_3 ) (a, d) - (c_{-1}) (c, b)
(y_7, y_1)= ( c_7 ) (a, d) + ( c_3 ) (c, b)
( c_7 )= [c_4]( c_3 ),
( c_3 )= [c_4](c_{-1}),
[c_4]= 1/√2( 1 -1
1 1 )
であるから、
(i, j)= ( c_3 )(a, d),
(k, l)= (c_{-1})(c, b)
を先に求めておき、( 2 回の 回転 = 6 回の乗算 + 6 回の加減算)
(y_3, y_5)= (i, j) - (k, l) (y_7, y_1)= [c_4]((i, j) + (k, l))と、さらに 6 回の加減算と、2 回の 1/√2 の乗算で完了する。
step 1 の 8 回の加減算、step 2 の偶数係数に 3 回の乗算と 9 回の加減算、 step 3 の奇数係数に 8 回の乗算と 12 回の加減算、を合計して、11 回の乗算と 29 回の加減算が 8 点 DCT の計算量となる。以上 DCT の高速アルゴリズム を説明したが IDCT はこの計算を逆にたどることで計算でき、計算量は DCT と 同じになる。
92 年 3 月 Haifa 会合には "List of Reqirements for MPEG-2 Video" と "Guide for the Video Work"をまとめている。 92 年 7 月のリオ会合では "Guide for the Video Work" の中に、 "Syntax と Toolkit" という章を設け、Toolkit 標準の方向への 期待がある。その後、11 月のロンドン会合では Reqirement Group のなかで、ISO で使われる "Profile" の定義が議論の表に出てきた。
これらは MPEG-2 の様々な用途を考慮すると、単一の標準では ありえないとする意見が多くなってきていたためである。 例えば、通信は B-picture を使わなかったり、 I-picture を使わないかもしれない。放送でもやはり、 B-picture を使わないという意見がある。 MPEG-1 や、 H.261 との Compatibility を保つことが重要な用途もあり、 コンピュータ上などで、小さい絵をだせることを重要視する、 Scalability という方向もある。さらには、HDTV との "Interlace to Interlace Scalability" という難題を解決しようとしている人もいる。 それらすべての応用を MPEG-2 の標準の単一の規格のなかに入れようとしても もはや無理である。そのために "Profile" という言葉の定義が行なわれる ようになった。
標準は用途にあわせた複数のプロファイルからなり、プロファイルは 標準化会議に管理されるのである。互換性を保持するために "Core" プロファイル(後に "Main"プロファイルをなった。)を考え、Core も、 ひとつの Profile であるとする。 Core は最小の部分ではない。 Core Profile より小さい部分も使ってよい。 しかし、互換性は Core の部分でしか達成されないだろうとする。 互換性が保たれる範囲というのは非常に重要なものなので、Core Profile を 決める事は技術の取捨選択であり、非常に微妙なものとなった。
"Core Profile は恐らく、 Random Access と、編集性はサポートするだろう。 Scalability, Compatibility はサポートしないだろう、 I,P,B ともサポートするだろう、 420 の 8bitになり、 422 は含めないだろう、Frame/field 予測 だけだろう"、というような文章がロンドン会合では出てきた。
これに付随して画面サイズによる"level" の定義がはじまった。 まず主要な画面サイズとして、通常のテレビジョン画像のサイズである、 ITU-R 601 とした。
93 年 1 月のローマ会合では "Core" という言葉が "Main" と置き換えられた。 Main profile は I,P,B ピクチャーを含む、frame/field 構造、420 であること、 エラー耐性がはいる等とした。Low delay profile は Main profile に含まれ、 Main profile は、Scalability, Compatibility profile に含まれるという 包含関係をもつことが望まれた。
これ以降、プロファイルとレベルの議論は収束したわけではなく、 いまだに変化している。これを要約的に説明すると、
93 年 3 月のシドニー会合では Profile は Simple, Main, Next の 3 種類となり、 level は High level, Main level, Low level の 3 種類となった。 High level とは HDTV サイズであり、low level とは CIF, SIF サイズである。
MP@ML (Main profile @ Main level) の技術的内容を凍結した。 Frame/field予測と Dual prime 予測を確定し、Simple, Next については、 Simple は B-picture なし、Dual prime なし。Next は Spatial scalability, と SNR scalabilityで構成されるとした。
同年 7 月の ニューヨーク会合では High Level が分離して High level (水平画素 1920)と High-1440 (水平画素1440)になった。 Simple High level が重要とみなされた。 Simple が B-picture なし、Dual prime ありとなった。
さらに 9 月のブリュッセル会合では Profile が分離して、 Simple, Main, Main+ と Next になった。 Main+ は Spatial scalability, SNR scalability をサポートする。 Next はさらに 422 をサポートする。また、Simple High, Simple High-1440 は消えた。
空間的な階層符号化を用いることで、強い意味の互換性が達成できる ことは明らかである。逆ピラミッド型の画像構造を考えて、 低位の小さい画像の符号化は既存の符号化の仕組みを用い、 上位の大きい画像の符号化には低位の画像を利用した残差の符号化をする。 そうすると低位の符号はそのまま既存のデコーダにかかるのである。 これを MPEG-2 から MPEG-1 への逆方向互換性(backward compatibility) という。
ところが、階層的符号化を用いることは、フルサイズの画像の符号化としては 基本的に有害であることがしだいに明確となった。低位を分離して符号化する ことが効率を低下させるのである。そのため、どうしても両方の画像が必要 な場合の方式である、サイマルキャスト(フルサイズと縮小画像の符号の並列 伝送、同時放送) との比較でやっと 1 dB 程度の有利さが示されてきた。 この程度の有利さは方式の複雑さを考慮すると選択に悩むところである。
Main profile は逆方向(backward)コンパティビリティを捨てることに なるだろうとは 92 年の前半に明確になっていた。 93 年のシドニー会合では Main profile が 順方向互換性(forward compatibility) をもつ形になった。 つまり Main profile のデコーダは MPEG-1 の ビットストリームもデコードできる形になった。
結果的に実現された構成は Main Profile では "スーパーセット" であり、 シンタックスは MPEG-1 の Extension に入っている。 Next では階層符号化による "エンベッデド" であり、逆方向(backward) コンパティビリティをも持つものである。
・上方向互換性(upward compatibility):
高解像度受信機が低解像度エンコーダからの信号から画像をデコードできること。
・下方向互換性(downward compatibility):
低解像度受信機が高解像度エンコーダからの信号またはその一部から画像をデコードできること。
下方向互換性には次の 2 つの手法がある。(a) デコーダが低解像度の全部の画像を再構成する、 (b) デコーダは画像の一部のウインドウを再構成する、 一般には (a) を意味する。フレームレートは必ずしも等しい必要はない。
また、伝送系に"異なる標準"の画像エンコーダとデコーダが使われるときには次の言葉が使われる。
・順方向互換性(forward compatibility):
新標準のデコーダが、
既存の標準のエンコーダからの信号またはその一部から画像をデコードできること。
・逆方向互換性(backward compatibility):
既存の標準のデコーダが、
新標準のエンコーダからの信号またはその一部から画像をデコードできること。
互換性を満たすためのエンコーダでの構成手法が明確化された。
・サイマルキャスト:
MPEG-1 と MPEG-2 の 2 つのエンコーダ出力をマルチプレックスする。
逆方向と下方互換性が可能。
・エンベッデド:
MPEG-1 のエンコーダと、それからの信号を利用した残差符号化をする
MPEG-2 エンコーダとを使う。順逆上下互換性が可能。
・スーパーセット:
MPEG-2 のシンタックスが MPEG-1 のシンタックスと、
Extension Syntaxからなること。順方向と上方向互換性が可能。
・スイッチャブル:
MPEG-1 と MPEG-2 の 2 つのエンコーダが切り替えられる仕組み。
両方の標準のモードがあれば順逆互換性が可能で、両方の分解能があれば
上下互換性が可能。
空間的スケーラビリティでは小さい画像からの画素拡大( up-sample )と 通常のフルサイズからの予測との切り替えや、時空間重み付けが議論されてきた。 10 Mbps 上限がなくなってからは HDTV と 通常の TV との"interlace to interlace" のスケーラビリティが重要視された。
・周波数スケーラビリティ
スケーラビリティを DCT係数空間での処理で実現するもの。DCT 係数空間(周波数空間)
の低域のみの IDCT で縮小画像を得ることができる。
また、縮小画像上の予測が行なわれるが、インターレース画像には大きな問題があった。
フレーム/フィールド適応予測と適応 DCT が使えないのである。
周波数スケーラビリティでは縮小画像上の予測誤差を符号化するかどうかで、 シングルループと、マルチループの 2 つの手法があり、 マルチループはドリフト(縮小画像の順次的劣化)を防ぐ能力がある。
ニューヨーク会合では数多くあった周波数スケーラビリティの手法は 大幅に収束し、ローマ会合ではデコーダはシングルループであると 確定した。ローマ会合では 2 つのスケーラビリティのグループ は統合され、シドニー会合では周波数スケーラビリティは姿を消した。 SNR スケーラビリティというものが出てきて、周波数 スケーラビリティを呑み込んでしまったのである。
・SNR スケーラビリティ
異なる粗さで量子化された DCT 係数を複数の階層として扱うことを SNR スケーラビリティという。
粗く量子化された画像が低ビットレートで供給でき、 上位階層では細かく量子化された残差の DCT 係数を下位階層の DCT 係数に加算してから IDCT を行う。デコーダは VLC デコーダから逆量子化までを 2 重化する必要がある。 周波数スケーラビリティは、下位階層の DCT 係数の範囲が制限されている SNR スケーラビリティとみることができる。 周波数スケーラビリティは低位の画像の質は SNR スケーラビリティによるものより良くはないという。
さらに I ピクチャの使用は符号量変動を吸収する大きなバッファを必要とし、 バッファ遅延が大きくなるため、I ピクチャを用いない符号化を考える事が 重要で、I スライスまたは I コラムという P ピクチャのなかに分散した Intra 符号化がよいとされる。
また、さらに予測の漏れを与える、 リーキー予測というものが検討された。 これは予測の精度を常に低下させることで Intra 処理を不用にしようとするものであるが予測の仕組みに大きく影響し、 予測精度を故意に低下させるものである。 そのような性質の悪さによって、リーキー予測はほとんど消えたが、 シドニー直前まで生き残った AC リーキーという仕組みは、 シドニーでは Main プロファイルには入らないとし、 ニューヨークではすべてのプロファイルに入らないとされた。
現在の NTSC 圏での 525 本インターレースはその丁度 2 倍の 1050 本と相性がよく、 PAL 圏では 625 本の 丁度 2 倍は 1250 本である。 1125 本の走査線本数は、 両者を折衷させるために作られたものであり、NTSC, PAL 圏両者の乗り合わせを意図している。
シドニー後のニューヨーク会合で、High level は 水平画素数 1920 と 1440 とによって High level と High-1440 level に分離した。 ヨーロッパは縦方向の本数が大きいので、メモリ量から 1440 を必要としたのである。
これに関連して現在、米国の ATV の 1050 本と、日本の 1125 本用の 1035 本符号化をなくして、 スクエアピクセルの1080 本に統合しようという大きな動きがあるらしい。 1993 年 10 月 25 日には電波新聞で、 G.A. がついにMPEG を受け入れ、 Main プロファイル High レベルで放送をするということを報道している。
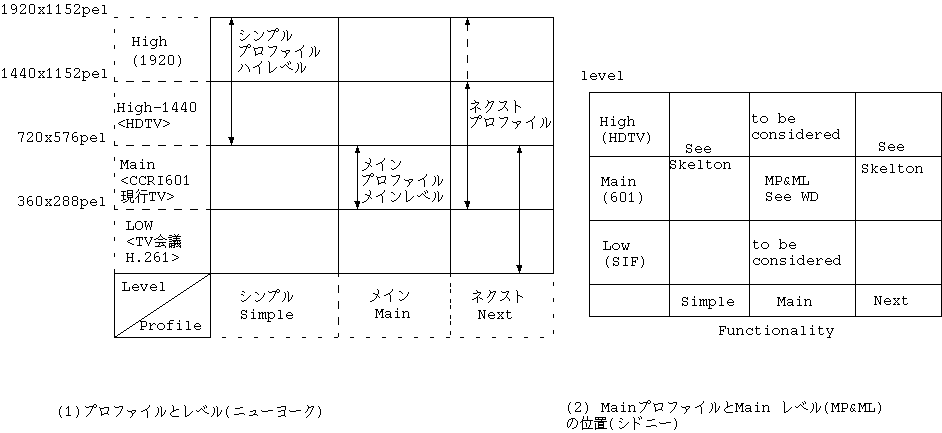 図 22 プロファイルの変遷
図 22 プロファイルの変遷
Main 以外のプロファイルである、Next と Simple プロファイルも議論されたが、 これについてはニューヨーク会合報告の中で説明する(図 22(a),(b) )。
Main プロファイルのシンタックスが決定された。MPEG-2 のデコーダは MPEG-1 のビットストリームを受けられるようにスーパーセットシンタックスとなり、 MPEG-1 から MPEG-2 へのフォワードコンパティビリティ(順方向互換性)が 保たれた(図 23 )。
 図 23 MPEG-2 の順方向互換性
図 23 MPEG-2 の順方向互換性
MPEG-1 と同じ Sequence header の直後に Sequence extension が存在する ことで、 MPEG-2 であることが判別される。MPEG-2 では Extension と User data は 前後関係はなく、挿入も任意であるが、MPEG-2 の中の MPEG-1 のシンタックスでは Extension の記述はなくなった(図 24 )。GOP が必須でなくなり、ピクチャレイヤと 対等となった。
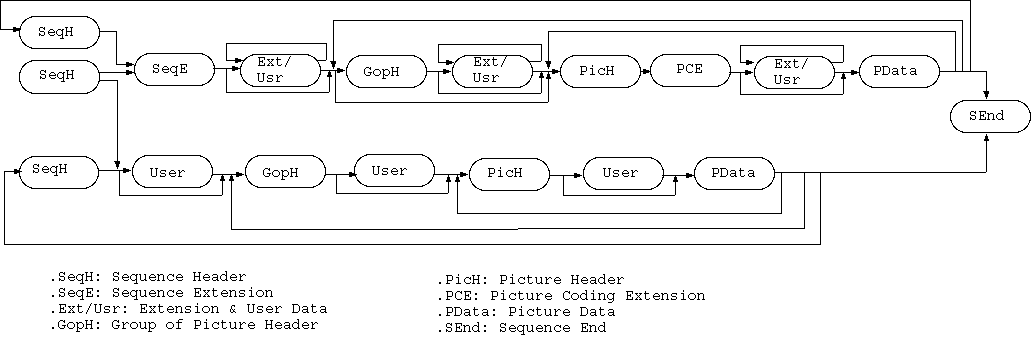 図 24 MPEG-2 のシンタックスフロー
図 24 MPEG-2 のシンタックスフロー
Main プロファイルには以下の 5 つの Extension が関係する。
・Sequence extension には他のすべての extension と同じく、extension start code と extension id をもつ。 その後に、profile and level id がプロファイルとレベル を記述する。non interlaced sequence, chroma format が記述される。 画面サイズは 14 bit x 14bit となり、bit rate, vbv buffer size も拡張された。
・Sequence display extension では、RGB からの 変換係数、 ガンマ特性の記述が可能 となった。
・Quant matrix extension の独立によって Quant matrix の変更が Sequence header だけ でなく、 Picture header の後にも行なえるようになった。420 のメインプロファイル では 2 つの Quant Matrix のままである。
・Picture coding extension では 符号化に関係する多くのパラメータ類が書かれる。 これについては後のメインプロファイルのシンタックス補足の項で説明したい。
・Picture pan scan extension では 12 bit + 4 bit(1/16ペル)の Pan/scan が用意され た。これは後のニューヨーク会合で、offset が 符号化画像中心から表示画像中心への 0 中心の 符号付き値となった。(図 25 )。 3/2 プルダウンへの対応も行なわれた。(図 26)
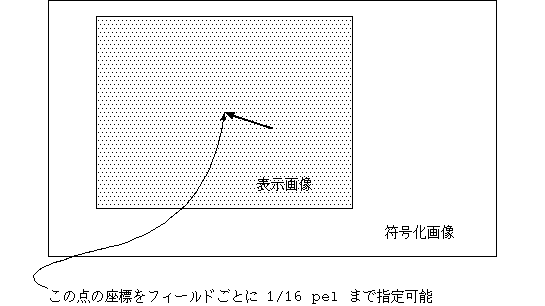 図 25 Pan/Scan
図 25 Pan/Scan
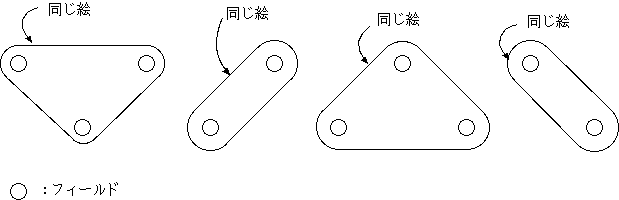 図 26 3/2 プルダウンのイメージ
図 26 3/2 プルダウンのイメージ
TM0 からの frame/field 予測と frame/field DCT、高級予測では Dual prime 予測、 Alternate scan と Alternate VLC ( ともに piucture layer での切り替え )、 高画質要求のための DC 精度と AC 精度、非線形 MQUANT、 新しい IDCT ミスマッチ対策、intra MV である。
この意味も多少変更され、第 1フィールド, 第 2 フィールドを意味するの ではなく、空間的に top であるか bottom であるかを示すようになった。 さらに、フレームピクチャでは top field first という項目が picture coding extension に設けられ、 top field が先か後かを示し、 その両方の構造を受け入れるようにした。フィールドピクチャでは どちらが先に来たかは明確であるから、 top field first はつねに 0 である。
フレームピクチャでは、 予測の種類としては、frame/field 予測、Dual prime 予測を備えていて、 ブロック配置の方法として、フレーム/フィールド適応 DCT を備えている。 フィールドピクチャでは、field 予測、16x8 予測、Dual prime 予測 を備える。
予測参照フィールドは、ある方向についてつねに 2 フィールドである。 以前、参照画像がフィールドであるかフレームであるかを表していた、 forward reference fields, backward reference fields,の各 2 bit は なくなった。
参照画面は両パリティのフィールドとし、 field 予測、16x8 予測のときはどちらのフィールドからか(Bottom/Top)を 個々の動きベクトルに、motion vertical field select という 1 bit を 付けて示すことになった。Dual prime は field 型の予測であるが 参照フィールドの両方からの予測を使うのでこの 1 bit はつかない。
" 2 つの参照フィールドはつねに異なるパリティのフィールドである。 順方向予測においては、 予測されるものが B-picture であるときと、 P-frame であるときは時間的に先行する最近に伝送された 2 フィールドである。 予測されるものが P-field であるときは参照フィールドはことなり、 最初に転送される field の予測にはすでに転送された I,P-frame であり、 つぎに転送される field の予測には、2 つの参照フィールドのひとつは同じフレームをなす 最初のフィールドであり、もう一つは過去に転送された I,P-frame の予測される field と同じパリティをもつ field である。逆方向予測においては、最近に転送された I,P-frame である。"
この文章はまだ多少の不正確さを含んでいるが、言わんとするところは明解である。 つぎの例において、I1, P2, P3, P4 が field picture であるとき、 P2 は I1 から予測する。 P3 は I1 と P2 から予測し、 P4 は P2 と P3 から予測する。 (図 27)
B-field を含む下の例では、P4 の参照フィールドは大きく離れた P2 と P3 となる(実線)。 B5, B6 の順方向参照フィールドは I1, P2 であり、逆方向参照フィールドは P3, P4 である(点線)。 (図 28 )
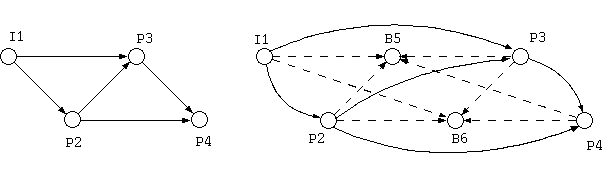
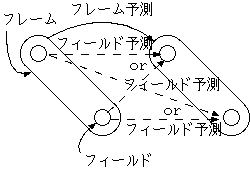 図 29 フレーム/フィールド予測
図 29 フレーム/フィールド予測
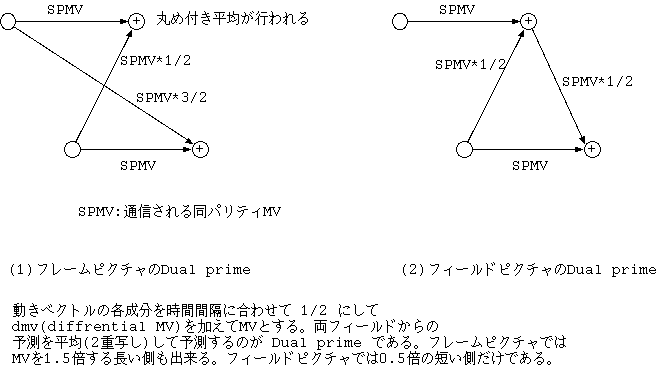 図 30 Dual prime予測
図 30 Dual prime予測
異パリティベクトル even to odd, odd to even の計算には、 同パリティベクトルから、参照フィールドと予測されるフィールドの間の 時間間隔である、フィールド間隔を使って換算して、さらに異パリティ用 の動ベクトルの差分(+1,0,-1)を使って修正して 2 つの (フィールドピクチャでは 1 つの)異パリティベクトルを求める。
M= 1 に制限されたため、フレームピクチャの場合には、異パリティベクトル の長さは、同パリティベクトルの長さの 0.5 倍と 1.5 倍の 2 種類になる。 フィールドピクチャでは参照フィールドのルールから異パリティベクトルは 同パリティベクトルの 0.5 倍だけとなる。
mv1.x = ( spmv.x * 1 )//2 + dmv.x ;
mv1.y = ( spmv.y * 1 )//2 + dmv.y - 1 ;
mv2.x = ( spmv.x * 3 )//2 + dmv.x ;
mv2.y = ( spmv.y * 3 )//2 + dmv.y + 1 ;
dmv.x = { 1, 0, -1 }
dmv.y = { 1, 0, -1 }
この式で、 // は丸めつき割り算であり、丁度 0.5 は 0 から遠ざける方向
に丸める。
mv1 はフィールド間隔の短い側の予測に使われる動きベクトルであり、 mv2 は長い側に使われる動きベクトルである。この式の mv1 の y 成分の -1 は top_field_first = 1 のときに短い側の予測が bottom から top への予測になるため half pel で、+1 だけシフトするのを防ぐために -1 を加算するためである。逆に top to bottom の予測であれば +1 となる。
フィールドピクチャの場合は 短い側のベクトル mv1 が、bottom to top の予測になるかどうかは現ピクチャの picture structure の値による。 現ピクチャが top であれば、bottom to top であり、bottom であれば、 top to bottom の予測である。
dmv の決定はエンコーダ側の事項であるが同パリティベクトルの候補として 4 つのフィールドベクトルをもとにした逆の換算による候補にそれぞれ x, y 方向それぞれに \{-1,0,+1\} で 9 種の探索を行い、36 種の中から 最適点を求めるのが TM の記述である。
Dual prime は Bus 等のシーケンスで、 4 M b/s の M= 1 では frame/field 予測と比較して、 1 dB 以上の SNR の向上をもたらした。順方向予測に、 B-picture の仕組みと同じ予測の平均の仕組みを使うわけであり、 M = 3 で は効果が 0.8 dB ( 上述の条件 )程度であるのと様々なフィールド間隔に 対応する必要があるため採用されなかった。通信目的の M=1 の予測精度を 向上させる目的で導入されたのである。
Dual prime は当初、P-picture だけでなく、B-picture の片方向予測にも 使うことを許した。Dual prime のメモリのバンド幅は B-picture の 内挿予測の field と変わらないため FAMC と比較して有利であり、 dmv による最適化があるので効果が大きい。ただしエンコーダ側の 負担は大きく、リアルタイムエンコードの必要な通信に使われること を疑問視する向きもある。
・AC 係数精度
量子化 AC 係数は MPEG-1 では +- 255 に制限されていたが、これを +2047 - -2048
まで拡張した。Escape + run + level の level が 12 bit になる。
MPEG-1 の 2 段階 escape は複雑であり、それを単一の 12 bit にする単純化である。
MPEG-2 は 12 bit 型の表現としたが、 MPEG-2 デコーダは MPEG-1 ビットストリーム
をデコードする必要があり、デコーダの簡単化にはならなかった。
・非線形 MQUANT
MPEG-1 では、MQUANT は 1 - 31 の線形であったが、非線形 MQUANT がピクチャ
レイヤで線形と切り替えられるようになった(下表)。
表15. 非線形 MQUANT
0 +1 +2 +3
0 禁止 0.5 1.0 1.5
4 2.0 2.5 3.0 3.5
8 4 5 6 7
12 8 9 10 11
16 12 14 16 18
20 20 22 24 26
24 28 32 36 40
28 44 48 52 56
 図 31 Alternate scan
図 31 Alternate scan
" すべての係数の和を奇数にするように、 それが偶数のとき、64 番目の係数の、符号と絶対値表現での最下位ビット (LSB)を反転する。" とシドニー会合では決めたけれども、 その後の Bitstream 交換での方法にしたがってニューヨーク会合では次のように 改められた。 " すべての係数の和を奇数にするように、 それが偶数のとき、[+2047,-2048]のクリッピングの後に、64 番目の係数の 2 の補数表現での最下位ビットを反転する。" なお、 Not Coded のブロックにはこの処理は行なわない。
ビットストリームシンタックスを分断して重要度を分けることで エラー耐性を得ようとする、PBP(プライオリティ ブレーク ポイント)は、 低いプライオリティのシンタックスの未定が多く、Main プロファイルには 不採用となった。
リーキー予測の中で残っていた AC リーキーも Main には不採用となり、ニューヨーク 会合で完全に不採用になった。
コンシールメントベクトルを使うときは、フレームピクチャでは フレーム予測、フィールドピクチャはフィールド予測と限定され、 次に述べる PMV は、イントラでもリセットされない。
これらは (1)スライス先頭と(2)コンシールメントベクトルのないときの Intra と (3) P-picture の Non MC でゼロベクトルにリセットされる。
順方向予測では、マクロブロックに 1 動きベクトル(1 MV/MB) である、 frame picture での frame MC と field picture での field MC と、 Dual prime では PMV1 を使用 (これとの差分を符号化しこれを 更新すること)し、 PMV2= PMV1 とする。
2 MV/MB である、frame picture の field MC と、 field picture の 16x8 MC では PMV1, PMV2 を Top と Bottom field に、または上下の サブマクロブロックに使用する。
逆方向予測 では PMV1, PMV2 の代わりに PMV3, PMV4 が使われる。
コンシールメントベクトルは順方向 1 MV/MB 予測であるため、 PMV1 を使い、PMV2= PMV1 とする。
この仕組みを図解すると(図 32)のようになる。矢印が MV の予測である。
 {\bf\dg 図 32 PMV のイメージ}
{\bf\dg 図 32 PMV のイメージ}1993年、 5 月 24 日、GI/Zenith, ATRC, AT\&T/MIT でグランドアライアンス (大同盟)が成立し、 Grand Alliance 案を MPEG-2 の Next profile として認めるよう MPEG に要求するという発表があった。
この GA 案は、スキャンフォーマットとして、1920x1080 のノンインタレース, スクエアピクセルを目指したものでその先進性に驚いたものである。 最初 1050 本インタレースでスタートし、最終的にスクエアピクセル、プログレッシブ とする。9 月 15 日までに決定するという。 現在、インタレースというアナログ時代の産物に MPEG も悩まされているわけ である。 MPEG-2 は符号化アルゴリズムにインタレースを取り込んだわけであるが、 カメラと表示系以外の伝送系においてはディジタル化によってインタレースの 利点は全くなくなっている。インタレースは、符号化だけでなく、画像の コンピュータ処理全般を難しくしている事はすべての技術者が認めることである。
ただし、これに記載してある画像符号化アルゴリズムは大したものがない。 (1) AC Leak (2) 8x8 inter/intra (3) No B-frame (4) VQ への Encoder 側の対応 (5) 再構成画像からの階層的 MV サーチなどを述べているが、 (1),(2) は Main profile への付加であり、(3) は除去であるため Next にも Simple にもなりえないというプロファイル間整合に問題があるし、 (2) はすでに MPEG で数多くの実験で否定された技術であり、(1) もあまり 有望とはみなされていない。(4),(5) はエンコーダ側の技術であり、勝手にやって くださいといっていい。未定事項として、B-picture をとるかどうかなど、9 月 30 日 までに決定するという。
伝送系については 4VSB, 6VSB, 32QAM, 32SS-QAM から 11 月 30 日までに 選択するという。また、 Audio については Dolby AC-3, Multi-channel MUSICAM, MIT-AC から 8 月 31 日までに選択するという。 (MPEG への要求は結果的には多少トーンダウンして、1920 x 1080 を認めるように という、米国 National Body の要求が出てきた。)
G.A.案の発表と同時期( 5 月 27 日 )、MIT のメディアラボの設立者 ネグロポンテ氏の米国下院(エネルギー通商委員会、通信財政小委員会) の公聴会での証言があり、 (1) FCC に対してはっきり否定的な態度を表明した。 (2) FCC が何年もかけてやってきたことは、完全に間違いであり、 プロセスを直ちに変更すべきである。 (3)符号化アルゴリズムは MPEG にまかせて、 FCC は伝送形式のみを扱うのが妥当である。 (4) 日本に対して放送のディジタル化を要求すべきである。 G7 の話題として宮沢首相は歓迎している。など述べている。 G7 当時、宮沢政権はすでに次期政権にとって代わられることがわかっていたため、 クリントンはこの話題を持ち出してないと思われる。
1993 年 7 月 12 日 から 16 日までコロンビア大学で行なわれた、 ニューヨーク会合ではいくつかの進展があった。Next プロファイルと Simple プロファイルが概略固まってきた。
9 月 6 日から 10 日まで行なわれたブリュッセル会合は Main プロファイルの不明点の解消と、Next, Simple の仕様の詰めが行なわれた。 Profile が増加した。Video の Main Profile シンタックスが一部変更された。
11 月 1 日から 5 日まで行なわれたソウル会合は MPEG-2 の すべてのプロファイルは技術的凍結を行ない、System, Video, Audio の CD (Committee Draft)13818-1,-2,-3 (ついでながら、MPEG-1 は ISO/IEC 11172-1,-2,-3 という番号であった。) が作成され、SC29 に提出され承認された。
ブリュッセル会合では、階層数を制限した。 Next と つぎに述べる Main+ の High レベルで ss=2 total=3 と変更し、 Main level の Main+ は ss=1 total=2 と変更した。
ニューヨークでは下位レイヤ(Base Layer)は 422 をサポートし、 MPEG-1,MPEG-2(MP),H.261 を使う事ができ、そのときそれらへの 逆方向互換性 (Backward compatibility) が成立する(図 34)とした。 ところが、H.261 との逆方向互換性はソウル会合で崩れた。
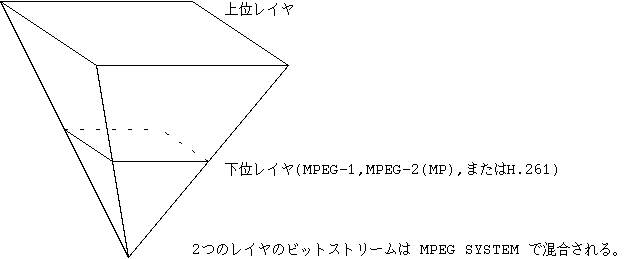 図 33 Next プロファイルのイメージ
図 33 Next プロファイルのイメージ
High X O X O
H-14 X O O(ss=2,total4=>3) O(ss=2,total4=>3)
Main O O O(ss=1,total3=>2) O(ss=2,total3)
Low X O O(ss=1,total2) X
Level/Profile Simple Main Main+ Next
図 35 プロファイルとレベル(ブリュッセル)
High X O X X O
H-14 X O X O O
Main O O O X O
Low X O O X X
Level/Profile Simple Main SNRP SSP High
図 36 プロファイルとレベル(ソウル)
ブリュッセル会合では、 (1) Slice の構造制限、すべてのプロファイルとレベルで、画面の左端には必ず Slice 先頭がくる。つまり、Slice は fold できず 1 行に収まるとした。 (2) B-field の skipped マクロブロックの明確化。 (3) f_code の不使用をしめす "1111"を採用。 (4) top_field_first と repeat_first_field の制約。 (5) D ピクチャは MPEG-1 のシンタックスの場合のみ使用可で、画面サイズは MPEG-2 の レベルが規定するとした。 (6)VBV の計算方法の変更、VBV が 3/2 pulldown に対応した計算が必要であり、 repeat_first_field は Picture の表示時間に関係し、デコードに要する時間を 一つ前の I,P ピクチャの表示時間であるとした計算となった。また、Skipped picture では Buffer underflow も許す。 (7)progressive_frame などの明確化。 (8) 10 bit 入力と 444 は標準の追記(addendum)として作業。 などが決まった。
ソウル会合では細かなものとしては、 (1) Temporal Scalability と Data partition そして、Frame rate extension は syntax 上は MPEG-2 に入っているが、どの Profile も使わないことが明確になった。 (2) intra slice が記述できるようになった。 (3)Sequence header で前の部分を切り去ったシーケンスも Regal とする。 (4) Field picture での PMV の 垂直 scaling はスケーリングなし。 (5) I,P field の P field での予測はつねに I field のみから。 (6) Slice Gap の処理は (0,0) のベクトルを使う順方向予測。ただし imformative とする。 (7)VBV buffer size は MP@ML で、1835008 bit MP@HL では 9786709 bitの 16 k bit 単位の数とする。 (8)VBV delay 制限は (2\^16 -1 )/90000= 0.73 sec とする。 (9)Dual prime の垂直ベクトルの範囲制限は 1.5 倍されて実際に使うときにかかる。 (10)マクロブロックの bit 数制限について、420 で 12 bit/pel, 422 で 16 bit/pel, 444 で 24bit/pel という制限を Conformance issure であるが、Informative part に記述。 (11)動きベクトル制限をプロファイルとレベル、水平垂直、フレームとフィールドピクチャ に分けて細かく記述した。 ( MP@LL の垂直は frame で[-64,63.5] field で [-32,31.5] 水平は f_code 7 まで、 MP@ML の垂直は frame で[-128,127.5] field で [-64,63.5] 水平は f_code 8 まで、 MP@H-14(HL) の垂直は frame で[-128,127.5] field で [-64,63.5] 水平は f_code 9 まで、 となった。) などである。
それに伴い、H.261 との Compatibility は非常に困難となった。 CD には MPEG-1 との Compatibility しか記述しなくなった。 H.261 との Compatibility は Simulcast で確保する、とした。これは互換性がないと いう意味ともとれる。
MPEG-1 を Base レイヤとする、 SNR Scalabilityでは、 Picture coding extension の default 値を設定し、下位レイヤが MPEG-1 であるときこの値であるとする。IDCT ミスマッチ対策の奇数化 は、Base レイヤが MPEG-1 の場合は MPEG-1 奇数化を含むことになった。
ソウル会合では基本的なしくみがかわり、ほとんどのディスプレイが スクエアピクセルであるか 4:3, または 16:9 の Display Aspect Ratio( DAR )を 持つことを利用した表現となった。
sample_aspect_ratio は aspect_ratio_information と名前を変え、 "0001" は PAR が 1.0 (square pel), "0010" は DAR が 3/4、 "0011" は DAR が 9/16 を表すとする。 aspect_ratio_information が DAR を規定する場合、sequence_display_extension() がないとき、
PAR = DAR * ( horizontal_size / vertical_size )
とし、sequence_display_extension() があるときは
PAR = DAR * ( display_horizontal_size / display_vertical_size )
とする。この変更により、 Pel Aspect Ratio は Sequence heder にあるにもかかわらず、 MPEG-1 との意味の互換性がなくなった。しかし Pel Aspect Ratio はデコーダは 素通ししてディスプレイに渡すだけなので重大問題とはならないと思う。
ソウルでもセミナーが行なわれた。特筆すべきは USNB の要求により、 "Very Low Bitrate Audio Visual Coding" というタイトルを "Very High Compression Rate Coding of Audio and Video" と 変更する案があった。この案は、最後の Plenary (全体会合)で反対をうけ、 各国の意見を次回 1994 年 3 月 のパリ会合にまとめることにした。
これは "Very Low Bitrate" というタイトルを持っていると、応用範囲が 限定され、移動体通信程度にしか使えないと見られるという危惧によるもの であろう。MPEG-2 の参加者が連続して MPEG-4 に参加することも難しい ようである。それを "Very High Compression Rate" とするだけで、 同じ技術を高い Bitrate にも使えるようになる。たとえば、米国の ディジタル放送会社(ヒューズ)などは HDTV を 2 Mbit/sec で符号化するような 標準化なら参加できるという。
これほどの圧縮率は、現在では無いものねだりであり、タイトルを変えても "Very High Compression Rate" はそう簡単には達成できるとは思えない。 MPEG-4 がビットレートを下げて再度標準化活動するのは、高級な符号化技術 の登場を招くためであり、ビットレートを 1/1000 に下げるのは、bit あたり の処理量を 1000 倍にも上げることができるからである。 また、MPEG-4 が元のタイトルで承認されたのであるから、勝手にタイトルを 変えようとしても、 SC29 より上の JTC1 に承認されなくなるかもしれない という考え方もある。
テクニカルレポートとして MPEG-1 のエンコーダ、デコーダのプログラム例 を作っていた作業は MPEG-1 の part 5 として出版されることになった。
画像符号化方式は、MPEG-2 Main プロファイルの High レベルを 採用し、世界標準との完全互換を確保したという。オーディオはドルビー AC3 に 決定。伝送の変調形式は SSQAM でなく、VSB を検討し、ヨーロッパの OFDM も 調査するとのことである。
その中で、Main プロファイルに関係するのは sequence_extension(), sequence_display_extension(), quant_matrix_extension(), picture_coding_extension(), picture_pan_scan_extension() の 5 つの extension である。
(1) profile_and_level_indication (8 ビット)
プロファイルとレベルを記述する。最上位の 1 ビット は Escape ビット で、通常 0 を使い、
次の 3 ビット はプロファイル ( Simple: 5, Main: 4, SNR Scalable: 3, Spatially
Scalable: 2, High: 1)で、 残りの 4 ビット はレベル ( Low: 10, Main: 8, High 1440: 6,
High: 4 )である。 MP@ML は 01001000 となる。
(2) progressive_sequence (1 ビット)
このビットが 1 のときは progressive_frame = 1 のフレームピクチャだけで
構成されるシーケンスである。この場合、デコード処理出力はプログレッシブ画像であり、
top_field_first と repeat_first_field は使えない。
このビットが 0 のときにピクチャはフレームピクチャとフィールドピクチャがありえ、 フレームピクチャのときに progressive_frame は 0 か 1 (各ピクチャ毎に異なりうる) でありえる。この場合、デコード処理出力はインターレースされたフィールドである。 デコード処理出力のフィールドは top と bottom を交互に繰り返さなければならないのは、 ビットストリームに対する要求である。(一番最初のフィールドは top でも bottom でもよい。)
プログレッシブフレームのデコード時にデコード処理出力が 2 または 3 の連続した フィールドであるとき、これらのフィールドがビットストリーム中の同じプログレッシブ フレームを基にしているという情報はディスプレイ処理に渡されなければならない。
(3) chroma_format (2 ビット)
420:01, 422:10, 444:11 を記述する。
(4) horizontal_size_extension (2 ビット)
水平サイズ値の上位 2 ビット。
(5) vertical_size_extension (2 ビット)
垂直サイズ値の上位 2 ビット。(4),(5)の 2 つの拡張により画面サイズは
14 ビット x 14ビット となる。
(6) bit_rate_extension (12 ビット)
ビットレートの上位 12 ビット の拡張。
(7) marker_bit (1 ビット)
値は 1 。
(8) vbv_buffer_size_extension (8 ビット)
バッファサイズの上位 8 ビット の拡張。
(9) low_delay (1 ビット)
1 のときには、シーケンスが B ピクチャを含まず、
VBV 記述にフレーム順番替えが現われず、スキップ画像 (VBV バッファのアンダーフロー)
が起こりうることを表す。 0 のときは、B ピクチャを含みえて、フレーム順替えの
ディレイが VBV 記述に現われ、スキップ画像が起こらないことを表す。
ブリュッセルでは B ピクチャの画像再配置ありなしを示し、バッファのアンダーフローを許す必要から、 No B かつ、allow underflow の意味の 1 ビット の設置が必要であるとして、 sequence extension のなかの、 frame rate extension の 8 ビット を 7 ビット にしてその前に 1 ビット "low delay" というフラグが付けられた。
(10) frame_rate_extension_n (2 ビット)
(11) frame_rate_extension_d (5 ビット)
これらの 2 項目はシンタクス上は入っているが、どの Profile も使わない仕組みである。
frame frame = frame rate value *(n+1)/(d+1) とする。
7 ビット の all 0 をあたえれば、 1/1 となって影響しない。
最後にすべての extension に共通だが、 next_start_code()で次のスタートコードをとる。
(1) video_format (3 ビット)
符号化前の画像が component: 0, PAL: 1,NTSC: 2, SECAM: 3,MAC: 4 を記述する。
(2) color_description (1 ビット)
これが 1 のとき以下の 24 ビット で次の (a)(b)(c)が続く。
(a)color_primaries (8 ビット) で、 RGB の色度の座標を記述する (ITU-R R709:1, Unspecified:2, ITU-R R624-4 System M: 4, ITU-R R624-4 System B,G:5, SMPTE 170M:6, SMPTE 240M: 7 )。
(b)transfer_characteristics (8 ビット)で、光電変換特性(ガンマ特性)を記述する (ITU-R R709:1, Unspecified:2, ITU-R R624-4 System M: 4, ITU-R R624-4 System B,G:5, SMPTE 170M:6, SMPTE 240M: 7 )。
(c)matrix_coefficients (8 ビット)で、RGB から輝度と色差信号を導く行列特性を記述する (ITU-R R709:1, Unspecified:2, FCC: 4, ITU-R R624-4 System B,G:5, SMPTE 170M:6, SMPTE 240M: 7 )。
(3) display_horizontal_size (14 ビット)
表示水平サイズ。
(4) display_vertical_size (14 ビット)
表示垂直サイズ。(3),(4)は pan_scan_extension()と aspect_ratio_information の解釈で使用する。
(1) load_intra_quant_matrix (1 ビット)
これが 1 のとき 8 x 64 ビット でジグザグ順に Intra 用量子化マトリックスを送る。
(2) load_non_intra_quant_matrix (1 ビット)
これが 1 のとき 8 x 64 ビット でジグザグ順に Non Intra 用 を送る。
同様に chroma intra, chroma non intra の量子化マトリクスの load flag が続くが、 色差用だけの量子化マトリックスは Main プロファイルでは使わない。
(1) forward_horizontal_f_code ( 4 ビット)
順方向水平用の f_code で、拡張ではなく置き換え。
(2) forward_vertical_f_code ( 4 ビット)
順方向垂直用の f_code で、拡張ではなく置き換え。 次に、逆方向用が続く。
(3) backward_horizontal_f_code ( 4 ビット)
逆方向水平用の f_code で、拡張ではなく置き換え。
(4) backward_vertical_f_code ( 4 ビット)
逆方向垂直用の f_code で、拡張ではなく置き換え。
(5) intra_dc_precision (2 ビット)
intra DC の精度の 8,9,10(,11) ビット を示す。
(6) picture_structure (2 ビット)
このピクチャがフレームかフィールドかを表す。01 が Top field (空間的に上のフィールド)、
10 が Bottom field、 11 がフレームである。
(7) top_field_first (1 ビット)
Top field が時間的に先である事を示す。フィールドピクチャ
ではデコーダはどちらのフィールドが先にくるかわかるので常に 0 を与える。
(8) frame_pred_frame_dct (1 ビット)
フレームピクチャで、この項目が 1 ならマクロブロックレイヤの motion_type,
dct_type は省略されて、全画面に frame MC かつ、frame DCT がとられる。
フィールドピクチャでは 0 でないといけない。
(9) concielment_motion_vectors (1 ビット)
intra マクロブロックに MV が付くことを表す。
(7) q_scale_type (1 ビット)
非線形 MQUANT を表す。
(8) intra_vlc_format (1 ビット)
intra マクロブロックタイプ時に、別の intra 用の
run-level 2 次元 VLC が使われる事を表す。
(9) alternate_ scan (1 ビット)
ジグザグでない別のスキャンが使われる事を表す。
(10)repeat_first_field (1 ビット)
3/2 pull down の 3 フィールドへの表示を表し、フィールドピクチャ
の場合と progressive_sequence が 1 の場合は常に 0 である。
(11) chroma_420_type (1 ビット)
フレームピクチャでは 420 から 422 への色差の縦方向拡大の処理を記述している。
これが 0 の場合はフィールド独立の拡大、1 のときは色差のフィールドのフレームへの結合を
アップサンプル以前に行なう。フィールドピクチャと、色差が 422, 444 では 0 とする。
(12) progressive_frame (1 ビット)
これが 0 のときは通常のインターレース表示で、2 つのフィールドが時間的差をもつ。
その場合、repeat_first_field = 0 とする制限がある。
これが 1 のときはプログレッシブ画面を表し、2 つのフィールドは同時の表示をする。 その場合、以下の制限がある。picture_structure = 3(frame), frame_pred_frame_dct= 1, chroma_format が 420 ならば、chroma_420_type =1(frame)。 このパラメタはSpatial Scalability の下位レイヤとして使われるときに使用される。 下位レイヤからの予測の up-sample filter に影響する。
(13) composite_display_flag (1 ビット)
以下の PAL 用の記述があることを示す。v_axis (1 ビット), field_sequence (3 ビット),
sub_carrier (1 ビット), burst_amplitude (7 ビット), sub_carrier_phase (8 ビット)である。
(1) frame_center_horizontal_offset (16 ビット)
(2) marker_bit (1 ビット) "1"
(3) frame_center_vertical_offset (16 ビット)
(4) marker_bit (1 ビット) "1"
これらで符号化画面上の表示の中心位置のオフセットを表示ごとに 1/16 画素精度で与えられる。表示数 n は、progressive_sequence = 1 であるか picture_structure = field であれば 1 であり、それ以外では、 repeat_first_field= 1 なら 3, そうでなければ 2 である。
1) INFORMATION THECHNOLOGY -
GENERIC CODING OF MOVING PICTURES AND ASSOCIATED AUDIO
Recommendation H.262
ISO/IEC 13818-2
Committee Draft
2) CQ 出版社 インターフェース 92 年 8 月号(pp 124-146)
"MPEG の概要と標準化動向"
3) CQ 出版社 インターフェース 92 年 10 月号(pp 241-244)
"MPEG標準化会議(Rio)報告"
4) CQ 出版社 インターフェース 93 年 3 月号(pp 205-213)
"'92 10月 MPEG 標準化会議とソフトウエア・デコーダの話題"
5)オーム社 エレクトロニクス 93年 5月号(p6-p12),6 月号(p8-p11)
"MPEG の最新情報"
6) C. Loeffler, A. Ligtenberg and G. Moschytz, "Practical Fast 1-D DCT Algorithms with 11 Multiplications", Proc. Int'l. Conf. on Acoustics, Speech, and Signal Processing 1989 (ICASSP '89), pp. 988-991.